
使用 OpenVINO 和 Postgres 构建快速高效的语义搜索系统
 浏览:573
浏览:573

照片由 real-napster 在 Pixabay上拍摄
在我最近的一个项目中,我必须构建一个语义搜索系统,该系统可以高性能扩展并为报告搜索提供实时响应。我们在 AWS RDS 上使用 PostgreSQL 和 pgvector,并搭配 AWS Lambda 来实现这一目标。面临的挑战是允许用户使用自然语言查询而不是依赖严格的关键字进行搜索,同时确保响应时间在 1-2 秒甚至更短,并且只能利用 CPU 资源。
在这篇文章中,我将逐步介绍构建此搜索系统的步骤,从检索到重新排名,以及使用 OpenVINO 和智能批处理进行标记化进行的优化。
语义搜索概述:检索和重新排序
现代最先进的搜索系统通常由两个主要步骤组成:检索和重新排名。
1) 检索:第一步涉及根据用户查询检索相关文档的子集。这可以使用预先训练的嵌入模型来完成,例如 OpenAI 的小型和大型嵌入、Cohere 的嵌入模型或 Mixbread 的 mxbai 嵌入。检索的重点是通过测量文档与查询的相似性来缩小文档池的范围。
这是一个使用 Huggingface 的句子转换器库进行检索的简化示例,这是我最喜欢的库之一:
from sentence_transformers import SentenceTransformer
import numpy as np
# Load a pre-trained sentence transformer model
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
# Sample query and documents (vectorize the query and the documents)
query = "How do I fix a broken landing gear?"
documents = ["Report 1 on landing gear failure", "Report 2 on engine problems"]
# Get embeddings for query and documents
query_embedding = model.encode(query)
document_embeddings = model.encode(documents)
# Calculate cosine similarity between query and documents
similarities = np.dot(document_embeddings, query_embedding)
# Retrieve top-k most relevant documents
top_k = np.argsort(similarities)[-5:]
print("Top 5 documents:", [documents[i] for i in top_k])
2) 重新排名:检索到最相关的文档后,我们使用交叉编码器模型进一步提高这些文档的排名。此步骤会更准确地重新评估与查询相关的每个文档,重点关注更深入的上下文理解。
重新排名是有益的,因为它通过更精确地评分每个文档的相关性来增加额外的细化层。
下面是使用 cross-encoder/ms-marco-TinyBERT-L-2-v2(轻量级交叉编码器)进行重新排名的代码示例:
from sentence_transformers import CrossEncoder
# Load the cross-encoder model
cross_encoder = CrossEncoder("cross-encoder/ms-marco-TinyBERT-L-2-v2")
# Use the cross-encoder to rerank top-k retrieved documents
query_document_pairs = [(query, doc) for doc in documents]
scores = cross_encoder.predict(query_document_pairs)
# Rank documents based on the new scores
top_k_reranked = np.argsort(scores)[-5:]
print("Top 5 reranked documents:", [documents[i] for i in top_k_reranked])
识别瓶颈:标记化和预测的成本
在开发过程中,我发现在使用句子转换器的默认设置处理 1,000 个报告时,标记化和预测阶段花费了相当长的时间。这造成了性能瓶颈,特别是因为我们的目标是实时响应。
下面我使用 SnakeViz 分析了我的代码以可视化性能:
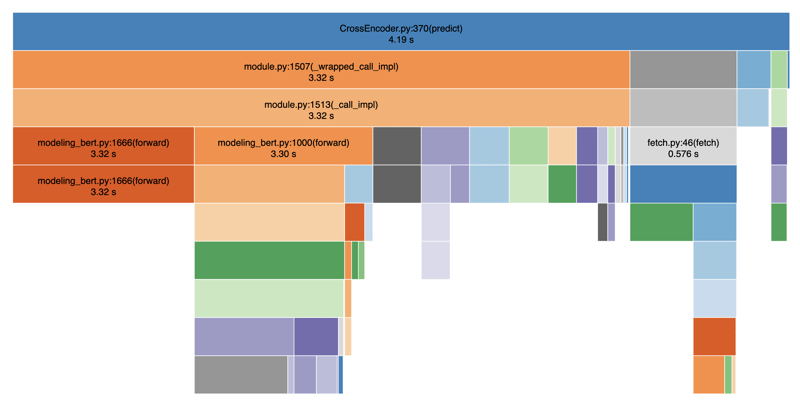
正如您所看到的,标记化和预测步骤异常缓慢,导致提供搜索结果的严重延迟。总的来说,平均需要 4-5 秒。这是因为标记化和预测步骤之间存在阻塞操作。如果我们还添加其他操作,如数据库调用、过滤等,我们很容易就总共需要 8-9 秒。
使用 OpenVINO 优化性能
我面临的问题是:我们可以让它更快吗?答案是肯定的,通过利用OpenVINO,一个针对 CPU 推理的优化后端。 OpenVINO 有助于加速英特尔硬件上的深度学习模型推理,我们在 AWS Lambda 上使用该硬件。
OpenVINO 优化的代码示例
以下是我如何将 OpenVINO 集成到搜索系统中以加快推理速度:
import argparse
import numpy as np
import pandas as pd
from typing import Any
from openvino.runtime import Core
from transformers import AutoTokenizer
def load_openvino_model(model_path: str) -> Core:
core = Core()
model = core.read_model(model_path ".xml")
compiled_model = core.compile_model(model, "CPU")
return compiled_model
def rerank(
compiled_model: Core,
query: str,
results: list[str],
tokenizer: AutoTokenizer,
batch_size: int,
) -> np.ndarray[np.float32, Any]:
max_length = 512
all_logits = []
# Split results into batches
for i in range(0, len(results), batch_size):
batch_results = results[i : i batch_size]
inputs = tokenizer(
[(query, item) for item in batch_results],
padding=True,
truncation="longest_first",
max_length=max_length,
return_tensors="np",
)
# Extract input tensors (convert to NumPy arrays)
input_ids = inputs["input_ids"].astype(np.int32)
attention_mask = inputs["attention_mask"].astype(np.int32)
token_type_ids = inputs.get("token_type_ids", np.zeros_like(input_ids)).astype(
np.int32
)
infer_request = compiled_model.create_infer_request()
output = infer_request.infer(
{
"input_ids": input_ids,
"attention_mask": attention_mask,
"token_type_ids": token_type_ids,
}
)
logits = output["logits"]
all_logits.append(logits)
all_logits = np.concatenate(all_logits, axis=0)
return all_logits
def fetch_search_data(search_text: str) -> pd.DataFrame:
# Usually you would fetch the data from a database
df = pd.read_csv("cnbc_headlines.csv")
df = df[~df["Headlines"].isnull()]
texts = df["Headlines"].tolist()
# Load the model and rerank
openvino_model = load_openvino_model("cross-encoder-openvino-model/model")
tokenizer = AutoTokenizer.from_pretrained("cross-encoder/ms-marco-TinyBERT-L-2-v2")
rerank_scores = rerank(openvino_model, search_text, texts, tokenizer, batch_size=16)
# Add the rerank scores to the DataFrame and sort by the new scores
df["rerank_score"] = rerank_scores
df = df.sort_values(by="rerank_score", ascending=False)
return df
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description="Fetch search results with reranking using OpenVINO"
)
parser.add_argument(
"--search_text",
type=str,
required=True,
help="The search text to use for reranking",
)
args = parser.parse_args()
df = fetch_search_data(args.search_text)
print(df)
通过这种方法,我们可以获得 2-3 倍的加速,将原来的 4-5 秒减少到 1-2 秒。完整的工作代码位于 Github 上。
速度微调:批量大小和标记化
提高性能的另一个关键因素是优化令牌化流程并调整批量大小和令牌长度。通过增加批量大小(batch_size = 16)和减少令牌长度(max_length = 512),我们可以并行化令牌化并减少重复操作的开销。在我们的实验中,我们发现 16 到 64 之间的 batch_size 效果很好,任何更大的值都会降低性能。同样,我们将 max_length 设置为 128,如果报告的平均长度相对较短,则该值是可行的。通过这些更改,我们实现了 8 倍的整体加速,将重新排名时间缩短至 1 秒以下,即使在 CPU 上也是如此。
在实践中,这意味着尝试不同的批量大小和令牌长度,以找到数据速度和准确性之间的适当平衡。通过这样做,我们看到响应时间显着缩短,使得搜索系统即使有 1,000 份报告也可扩展。
结论
通过使用 OpenVINO 并优化标记化和批处理,我们能够构建一个高性能语义搜索系统,满足仅 CPU 设置的实时要求。事实上,我们的整体速度提升了 8 倍。使用句子转换器的检索和使用交叉编码器模型的重新排名相结合,创造了强大的、用户友好的搜索体验。
如果您正在构建响应时间和计算资源受到限制的类似系统,我强烈建议您探索 OpenVINO 和智能批处理以释放更好的性能。
希望您喜欢这篇文章。如果您觉得这篇文章有用,请给我一个赞,以便其他人也可以找到它,并与您的朋友分享。在 Linkedin 上关注我,了解我的最新工作。感谢您的阅读!
-

-
在细胞编辑后,如何维护自定义的JTable细胞渲染?在JTable中维护jtable单元格渲染后,在JTable中,在JTable中实现自定义单元格渲染和编辑功能可以增强用户体验。但是,至关重要的是要确保即使在编辑操作后也保留所需的格式。在设置用于格式化“价格”列的“价格”列,用户遇到的数字格式丢失的“价格”列的“价格”之后,问题在设置自定义单元格...编程 发布于2025-07-03
-
在Java中使用for-to-loop和迭代器进行收集遍历之间是否存在性能差异?For Each Loop vs. Iterator: Efficiency in Collection TraversalIntroductionWhen traversing a collection in Java, the choice arises between using a for-...编程 发布于2025-07-03
-
input: Why Does "Warning: mysqli_query() expects parameter 1 to be mysqli, resource given" Error Occur and How to Fix It? output: 解决“Warning: mysqli_query() 参数应为 mysqli 而非 resource”错误的解析与修复方法mysqli_query()期望参数1是mysqli,resource给定的,尝试使用mysql Query进行执行MySQLI_QUERY_QUERY formation,be be yessqli:sqli:sqli:sqli:sqli:sqli:sqli: mysqli,给定的资源“可能发...编程 发布于2025-07-03
-
如何使用Depimal.parse()中的指数表示法中的数字?在尝试使用Decimal.parse(“ 1.2345e-02”中的指数符号表示法表示的字符串时,您可能会遇到错误。这是因为默认解析方法无法识别指数符号。 成功解析这样的字符串,您需要明确指定它代表浮点数。您可以使用numbersTyles.Float样式进行此操作,如下所示:[&& && && ...编程 发布于2025-07-03
-
Java中Lambda表达式为何需要“final”或“有效final”变量?Lambda Expressions Require "Final" or "Effectively Final" VariablesThe error message "Variable used in lambda expression shou...编程 发布于2025-07-03
-
找到最大计数时,如何解决mySQL中的“组函数\”错误的“无效使用”?如何在mySQL中使用mySql 检索最大计数,您可能会遇到一个问题,您可能会在尝试使用以下命令:理解错误正确找到由名称列分组的值的最大计数,请使用以下修改后的查询: 计数(*)为c 来自EMP1 按名称组 c desc订购 限制1 查询说明 select语句提取名称列和每个名称...编程 发布于2025-07-03
-
如何干净地删除匿名JavaScript事件处理程序?删除匿名事件侦听器将匿名事件侦听器添加到元素中会提供灵活性和简单性,但是当要删除它们时,可以构成挑战,而无需替换元素本身就可以替换一个问题。 element? element.addeventlistener(event,function(){/在这里工作/},false); 要解决此问题,请考虑...编程 发布于2025-07-03
-
如何在鼠标单击时编程选择DIV中的所有文本?在鼠标上选择div文本单击带有文本内容,用户如何使用单个鼠标单击单击div中的整个文本?这允许用户轻松拖放所选的文本或直接复制它。 在单个鼠标上单击的div元素中选择文本,您可以使用以下Javascript函数: function selecttext(canduterid){ if(do...编程 发布于2025-07-03
-
如何限制动态大小的父元素中元素的滚动范围?在交互式接口中实现垂直滚动元素的CSS高度限制问题:考虑一个布局,其中我们具有与用户垂直滚动一起移动的可滚动地图div,同时与固定的固定sidebar保持一致。但是,地图的滚动无限期扩展,超过了视口的高度,阻止用户访问页面页脚。$("#map").css({ marginT...编程 发布于2025-07-03
-
左连接为何在右表WHERE子句过滤时像内连接?左JOIN CONUNDRUM:WITCHING小时在数据库Wizard的领域中变成内在的加入很有趣,当将c.foobar条件放置在上面的Where子句中时,据说左联接似乎会转换为内部连接。仅当满足A.Foo和C.Foobar标准时,才会返回结果。为什么要变形?关键在于其中的子句。当左联接的右侧值...编程 发布于2025-07-03
-
Python元类工作原理及类创建与定制python中的metaclasses是什么? Metaclasses负责在Python中创建类对象。就像类创建实例一样,元类也创建类。他们提供了对类创建过程的控制层,允许自定义类行为和属性。在Python中理解类作为对象的概念,类是描述用于创建新实例或对象的蓝图的对象。这意味着类本身是使用类关...编程 发布于2025-07-03
-
Java是否允许多种返回类型:仔细研究通用方法?在Java中的多个返回类型:一种误解类型:在Java编程中揭示,在Java编程中,Peculiar方法签名可能会出现,可能会出现,使开发人员陷入困境,使开发人员陷入困境。 getResult(string s); ,其中foo是自定义类。该方法声明似乎拥有两种返回类型:列表和E。但这确实是如此吗...编程 发布于2025-07-03
-
图片在Chrome中为何仍有边框?`border: none;`无效解决方案在chrome 在使用Chrome and IE9中的图像时遇到的一个频繁的问题是围绕图像的持续薄薄边框,尽管指定了图像,尽管指定了;和“边境:无;”在CSS中。要解决此问题,请考虑以下方法: Chrome具有忽略“ border:none; none;”的已知错误,风格。要解决此问题,请使用以下...编程 发布于2025-07-03
-
为什么不````''{margin:0; }`始终删除CSS中的最高边距?在CSS 问题:不正确的代码: 全球范围将所有余量重置为零,如提供的代码所建议的,可能会导致意外的副作用。解决特定的保证金问题是更建议的。 例如,在提供的示例中,将以下代码添加到CSS中,将解决余量问题: body H1 { 保证金顶:-40px; } 此方法更精确,避免了由全局保证金重置引...编程 发布于2025-07-03















学习中文
- 1 走路用中文怎么说?走路中文发音,走路中文学习
- 2 坐飞机用中文怎么说?坐飞机中文发音,坐飞机中文学习
- 3 坐火车用中文怎么说?坐火车中文发音,坐火车中文学习
- 4 坐车用中文怎么说?坐车中文发音,坐车中文学习
- 5 开车用中文怎么说?开车中文发音,开车中文学习
- 6 游泳用中文怎么说?游泳中文发音,游泳中文学习
- 7 骑自行车用中文怎么说?骑自行车中文发音,骑自行车中文学习
- 8 你好用中文怎么说?你好中文发音,你好中文学习
- 9 谢谢用中文怎么说?谢谢中文发音,谢谢中文学习
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









