
Google Geminiとは何ですか? GoogleのChatGptのライバルについて知る必要があるすべて
 ブラウズ:269
ブラウズ:269
Google recently released its new Generative AI model, Gemini. It results from a collaborative effort by a range of teams at Google, including members of Google Research.
The model, which Google refers to as the most capable and general-purpose AI they’ve developed thus far, was designed to be multimodal. This means Gemini can comprehend various data types such as text, audio, images, video, and code.
For the remainder of this article, we’re going to cover:
- What is Gemini?
- What are the versions of Gemini?
- How can you access Gemini?
- Gemini Benchmarks Explored
- Gemini vs. GPT-4
- Use-Cases For Gemini
What is Google Gemini?
On December 6, 2023, Google DeepMind announced Gemini 1.0. Upon release, Google described it as their most advanced set of Large Language Models (LLMs), thus superseding the Pathways Langauge Model (PaLM 2), which debuted in May of the same year.
Gemini defines a family of multimodal LLMs capable of understanding texts, images, videos, and audio. It’s also said to be capable of performing complex tasks in math and physics, as well as being able to generate high-quality code in several programming languages.
Fun fact: Sergey Brin, Google’s co-founder, is credited as one of the contributors to the Gemini model.
Until recently, the standard procedure for developing multimodal models consisted of training individual components for various modalities and then piecing them together to mimic some of the functionality. Such models would occasionally excel at performing certain tasks, like describing images, but they have trouble with more sophisticated and complex reasoning.
Gemini was designed to be natively multimodal; thus, it was pre-trained on several modalities from the beginning. To further refine its efficacy, Google fine-tuned it with additional multimodal data.
Consequently, Gemini is significantly more capable than existing multimodal models in understanding and reasoning about a wide range of inputs from the ground up, according to Sundar Pichai, the CEO of Google and Alphabet, and Demis Hassabis, CEO and Co-Found of Google DeepMind. They also state that Gemini’s capabilities are “state of the art in nearly every domain.”
Google Gemini Key Features
The key features of the Gemini model include:
1. Understanding text, images, audio, and more
Multimodal AI is a new AI paradigm gaining traction in which different data types are merged with multiple algorithms to achieve a higher performance. Gemini leverages this paradigm, meaning it integrates well with various data types. You can input images, audio, text, and other data types, resulting in more natural AI interactions.
2. Reliability, scalability, and efficiency
Gemini leverages Google’s TPUv5 chips, thus reportedly making it five times stronger than GPT-4. Faster processing makes Gemini capable of tackling complex tasks relatively easily and handling multiple requests simultaneously.
3. Sophisticated reasoning
Gemini was trained on an enormous dataset of text and code. This ensures the model can access the most up-to-date information and provide accurate and reliable responses to your queries. According to Google, the model outperforms OpenAI’s GPT-4 and “expert level” humans in various intelligence tests (e.g., MMLU benchmark).
4. Advanced coding
Gemini 1.0 can understand, explain, and generate high-quality code in the most widely used programming languages, such as Python, Java, C , and Go – this makes it one of the leading foundation models for coding globally.
The model also excels in several coding benchmarks, including HumanEval, a highly-regarded industry standard for evaluating performance on coding tasks; it also performed well on Google’s internal, held-out dataset, which leverages author-generated code instead of information from the web.
5. Responsibility and safety
New protections were added to Google’s AI Principles and policies to account for Gemini’s multimodal capabilities. Google says, “Gemini has the most comprehensive safety evaluations of any Google AI model to date, including for bias and toxicity.” They also said they’ve “conducted novel research into potential risk areas like cyber-offense, persuasion, and autonomy, and have applied Google Research’s best-in-class adversarial testing techniques to help identify critical safety issues in advance of Gemini’s deployment.”
What Are The Versions of Gemini?
Google says Gemini, the successor to LaMDA and PaLM 2, is their “most flexible model yet — able to efficiently run on everything from data centers to mobile devices.” They also believe Gemini’s state-of-the-art capabilities will improve how developers and business clients build and scale with AI.
The first version of Gemini, unsurprisingly named Gemini 1.0, was released in three different sizes:
- Gemini Nano — Gemini Nano is the most efficient model for on-device tasks that require efficient AI processing without connecting to external servers. In other words, it’s designed to run on smartphones, specifically the Google Pixel 8.
- Gemini Pro — Gemini Pro is the optimal model for scaling across various tasks. It’s designed to power Bard, Google’s most recent AI chatbot; thus, it can understand complex queries and respond rapidly.
- Gemini Ultra — Gemini Ultra is the largest and most capable model for complex tasks, exceeding the current state-of-the-art results in 30 of the 32 commonly used benchmarks for large language model (LLM) research and development.
How Can You Access Gemini?
Since December 13, 2023, developers and enterprise customers have been able to access Gemini Pro through Gemini’s API in Google AI Studio or Google Cloud Vertex AI.
Note Google AI Studio is a freely available browser-based IDE that developers can use to prototype generative models and easily launch applications using an API key. Google Cloud Vertex, on the other hand, is a fully managed AI platform that offers all of the tools required to build and use generative AI. According to Google, “Vertex AI allows customization of Gemini with full data control and benefits from additional Google Cloud features for enterprise security, safety, privacy and data governance and compliance.”
Through AICore, a new system feature with Android 14, Android developers, starting from Pixel 8 Pro devices, can build with Gemini Nano, the most efficient model for on-device tasks.
Gemini Benchmarks Explored
The Gemini models underwent extensive testing to assess their performance across a broad range of tasks before their release. Google says its Gemini Ultra model outperforms the existing state-of-the-art results on 30 of the 32 commonly used academic benchmarks for Large Language Model (LLM) research and development. Note these tasks range from natural image, audio, and video understanding to mathematical reasoning.
In an Gemini introductory blog post, Google claims Gemini Ultra is the first-ever model to outperform human experts on Massive Multitask Language Understanding (MMLU) with a score of 90.0%. Note that MMLU incorporates 57 different subjects, including math, physics, history, law, medicine, and ethics, to assess one’s ability to solve problems and a general understanding of the world.
The new MMLU benchmark method to MMLU enables Gemini to make significant improvements instead of merely leveraging its first impressions by using its reasoning power to deliberate more thoroughly before responding to challenging questions.
Here’s how Gemini performed on text tasks:
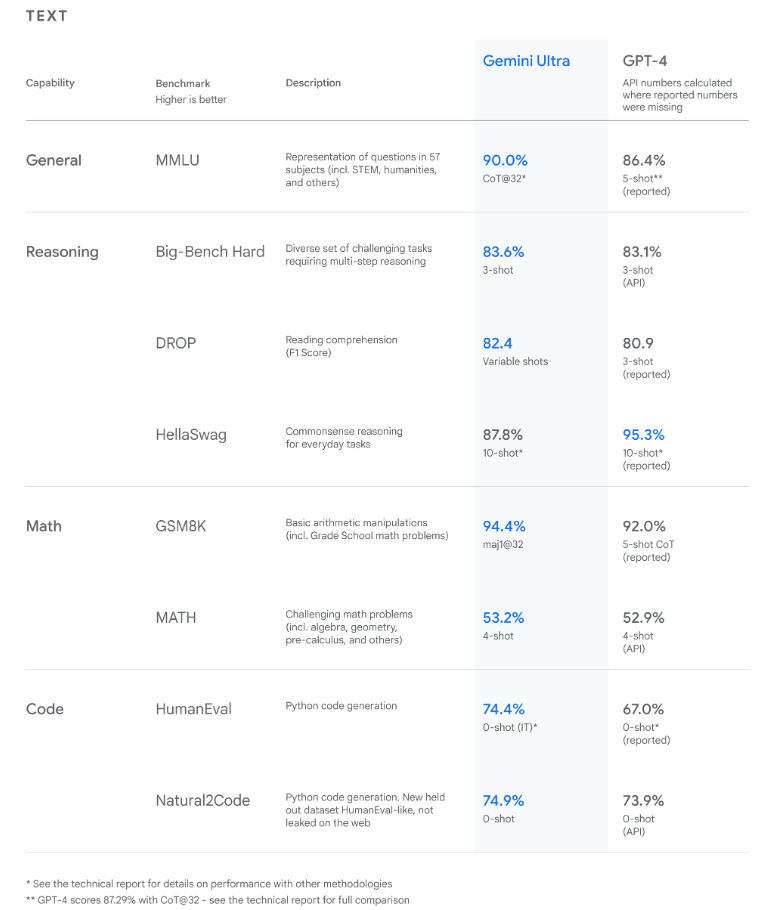
The findings reveal Gemini surpasses state-of-the-art performance on a wide range of benchmarks, including text and coding. [Source]
The Gemini Ultra model also achieved state-of-the-art on the new Massive Multidiscipline Multimodal Understanding (MMMU) benchmark with a score of 59.4%. This assessment consists of multimodal tasks across various domains requiring deliberate reasoning.
Google said, “With the image benchmarks we tested, Gemini Ultra outperformed previous state-of-the-art models without assistance from optical character recognition (OCR) systems that extract text from images for further processing.”
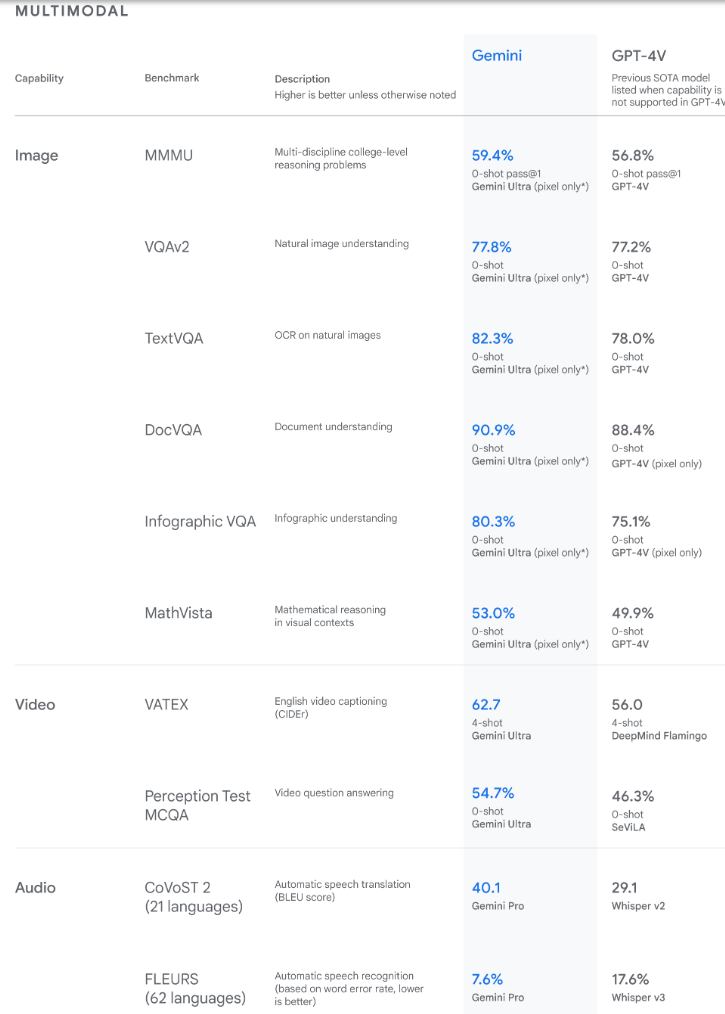
The findings reveal Gemini also surpasses state-of-the-art performance on a wide range of multimodal benchmarks. [Source]
The benchmarks set by Gemini demonstrate the model's innate multimodality and show early evidence of its capacity for more sophisticated reasoning.
Gemini vs. GPT-4
The obvious question that typically arises next is, “How does Gemini compare to GPT-4?”
Both models have similar feature sets and can interact with and interpret text, image, video, audio, and code data, enabling users to apply them to various tasks.
Users of both tools have the option to fact-check, but how they go about providing this functionality is different. Where OpenAI’s GPT-4 provides source links for the claims it makes, Gemini enables users to perform a Google search to confirm the response by clicking a button.
It’s also possible to augment both models with additional extensions, although, at the time of writing, Google’s Gemini model is much more limited.
For example, it’s possible to utilize Google tools such as flights, maps, YouTube, and their range of Workspace applications with Gemini. In contrast, there’s a far larger selection of plug-ins and extensions available for OpenAI's GPT-4, of which most are created by third parties. On-the-fly image creation is also possible with GPT-4; Gemini is designed to be capable of such functionality, but, at the time of writing, it cannot.
On the other hand, Gemini’s response times are faster than that of GPT-4, which can occasionally be slowed down or entirely interrupted due to the sheer volume of users on the platform.
Use-Cases For Gemini
Google’s Gemini models can perform various tasks across several modalities, such as text, audio, image, and video comprehension.
Combining different modalities to understand and generate output is also possible due to Gemini’s multimodal nature.
Examples of use cases for Gemini include:
Text summarization
Gemini models can summarize content from various data types. According to a research paper titled GEMINI: Controlling The Sentence-Level Summary Style in Abstractive Text Summarization, the Gemini model “integrates rewrites and a generator to mimic sentence rewriting and abstracting techniques, respectively.”
Namely, Gemini adaptively selects whether to rewrite a specific document sentence or generate a summary sentence entirely from scratch. The findings of the experiments revealed that the approach used by Gemini outperformed the pure abstractive and rewriting baselines on three benchmark datasets, achieving the best results on WikiHow.
Text generation
Gemini can generate text-based input in response to a user prompt - this text can also be driven by a Q&A-style chatbot interface. Thus, Gemini can be deployed to handle customer inquiries and offer assistance in a natural yet engaging manner, which can free up the responsibilities of human agents to apply themselves more to complex tasks and improve customer satisfaction.
It may also be used for creative writing, such as co-authoring a novel, writing poetry in various styles, or generating scripts for movies and plays. This can significantly boost the productivity of creative writers and reduce the tension caused by writer's block.
Text translation & Audio processing
With their broad multilingual capabilities, the Gemini models can understand and translate over 100 different languages. According to Google, Gemini surpasses Chat GPT-4V’s state-of-the-art performance “on a range of multimodal benchmarks,” such as automatic speech recognition (ASR) and automatic speech translation.
Image & video processing
Gemini can understand and interpret images, making it suitable for image captioning and visual Q&A use cases. The model can also parse complex visuals, including diagrams, figures, and charts, without requiring external OCR tools.
Code analysis and generation
Developers can use Gemini to solve complex coding tasks and debug their code. The model is capable of understanding, explaining, and generating in the most used programming languages, such as Python, Java, C , and Go.
Conclusion
Google’s new set of multimodal Large Language Models (LLMs), Gemini, is the successor to LaMDA and PaLM 2. They describe it as their most advanced set of LLMs capable of understanding texts, images, videos, audio, and complex tasks like math and physics. Gemini is also capable of generating high-quality code in many of the most popular programming languages.
The model has achieved state-of-the-art capability in various tasks, and many at Google believe it represents a significant leap forward in how AI can help improve our daily lives.
Continue your learning with the following resources:
- LlamaIndex: Adding Personal Data to LLMs
- The Top 10 ChatGPT Alternatives You Can Try Today
- Introduction to ChatGPT
And before you go, don't forget to subscribe to our YouTube channel. We have great content for all the most relevant and trending topics, including a tutorial on how to build multimodal apps with Gemini, so do have a look.
-
 AIエージェントとは何ですか? - 分析とアプリケーションガイドArtificial Intelligence (AI) is rapidly evolving, and 2025 is shaping up to be the year of AI agents. But what are AI agents...AI 2025-05-01に投稿
AIエージェントとは何ですか? - 分析とアプリケーションガイドArtificial Intelligence (AI) is rapidly evolving, and 2025 is shaping up to be the year of AI agents. But what are AI agents...AI 2025-05-01に投稿 -
PythonのOpenCVとRoboflowによる性別検出-AnalyticsVidhya導入 フェイシャル画像からのジェンダー検出は、コンピュータービジョンの多くの魅力的なアプリケーションの1つです。このプロジェクトでは、OpenCVを対立する場所と性別分類のためにRoboflow APIを組み合わせて、顔を識別し、それらをチェックし、性別を予測するデバイスを作成します。この直接は、コ...AI 2025-04-29に投稿されました
-
最初のマシン思考:戦略的AIの台頭STRATEGIC AI Prologue 11. May 1997, New York City. It was a beautiful spring day in New York City. The skies were clear, and temperatures were climbin...AI 2025-04-29に投稿されました
-
8 LLMの本質的な無料および有料API推奨事項LLMSの力の活用:大規模な言語モデルのAPIのガイド 今日のダイナミックなビジネスランドスケープでは、API(アプリケーションプログラミングインターフェイス)がAI機能の統合と利用方法に革命をもたらしています。 それらは重要な橋として機能し、大規模な言語モデル(LLM)を多様なソフトウェアエコ...AI 2025-04-21に投稿されました
-
ユーザーガイド:FALCON 3-7B指示モデルTIIのファルコン3:オープンソースの革新的な飛躍ai TIIのAIの再定義の野心的な追求は、Advanced Falcon 3モデルで新たな高みに達します。 この最新のイテレーションは、新しいパフォーマンスベンチマークを確立し、オープンソースAIの機能を大幅に進めます。 Falcon 3...AI 2025-04-20に投稿しました
-
deepseek-v3対gpt-4oおよびllama 3.3 70b:明らかにされた最強のAIモデルThe evolution of AI language models has set new standards, especially in the coding and programming landscape. Leading the c...AI 2025-04-18に投稿されました
-
トップ5 AIインテリジェントな予算編成ツールAIで金融の自由のロックを解除:インドのトップ予算編成アプリ あなたはあなたのお金がどこに行くのか絶えず疑問に思ってうんざりしていますか? 法案はあなたの収入をむさぼり食うようですか? 人工知能(AI)は強力なソリューションを提供します。 AI予算編成ツールは、リアルタイムの財務洞察、パーソナ...AI 2025-04-17に投稿されました
-
Excel Sumproduct機能の詳細な説明 - データ分析学校Excelの等式関数:データ分析Powerhouse 合理化されたデータ分析のためのExcelの等式関数の力のロックを解除します。この汎用性のある関数は、合計と乗算機能を簡単に組み合わせて、対応する範囲または配列全体の追加、減算、および分割に拡張します。 傾向を分析するか、複雑な計算に取り組む...AI 2025-04-16に投稿されました
-
詳細な調査は完全にオープンで、ChatGptとユーザーの利点がありますOpenaiの深い研究:AI研究のためのゲームチェンジャー Openaiは、すべてのChatGPTと加入者の深い研究を解き放ち、研究効率の大幅な後押しを約束しています。 Gemini、Grok 3、Perplexityなどの競合他社から同様の機能をテストした後、Openaiの深い研究を優れた選...AI 2025-04-16に投稿されました
-
Amazon Nova Today Real Experience and Review -AnalyticsVidhyaAmazonがNovaを発表する:強化されたAIおよびコンテンツ作成のための最先端の基礎モデル Amazonの最近のRe:Invent 2024イベントは、AIとコンテンツの作成に革命をもたらすように設計された、最も高度な基礎モデルのスイートであるNovaを紹介しました。この記事では、Novaの...AI 2025-04-16に投稿されました
-
ChatGPTタイミングタスク関数を使用する5つの方法ChatGptの新しいスケジュールされたタスク:ai で一日を自動化する ChatGptは最近、ゲームを変える機能:スケジュールされたタスクを導入しました。 これにより、ユーザーはオフライン中であっても、所定の時期に通知または応答を受信して、繰り返しプロンプトを自動化できます。毎日のキュレ...AI 2025-04-16に投稿されました
-
3つのAIチャットボットのうち、同じプロンプトに応答するのはどれですか?Claude、ChatGpt、Geminiなどのオプションを使用して、チャットボットを選択すると圧倒的に感じることができます。ノイズを切り抜けるために、同一のプロンプトを使用して3つすべてをテストに入れて、どちらが最良の応答を提供するかを確認します。すべてのツールと同様に、出力はそれを使用す...AI 2025-04-15に投稿されました
-
chatgptで十分で、専用のAIチャットマシンは必要ありません新しいAIチャットボットが毎日起動している世界では、どちらが正しい「1つ」であるかを決定するのは圧倒的です。しかし、私の経験では、CHATGPTは、プラットフォーム間を切り替える必要なく、私が投げたすべてのものを、少し迅速なエンジニアリングで処理します。 スペシャリストAIチャットボットは、多く...AI 2025-04-14に投稿されました
-
インドのAIの瞬間:生成AIにおける中国と米国との競争インドのAI野心:2025アップデート 中国と米国が生成AIに多額の投資をしているため、インドは独自のGenaiイニシアチブを加速しています。 インドの多様な言語的および文化的景観に対応する先住民族の大手言語モデル(LLMS)とAIツールの緊急の必要性は否定できません。 この記事では、インドの急...AI 2025-04-13に投稿されました
-
気流とDockerを使用してCSVのインポートをPostgreSQLに自動化するこのチュートリアルは、Apache Airflow、Docker、およびPostgreSQLを使用して堅牢なデータパイプラインを構築して、CSVファイルからデータベースへのデータ転送を自動化することを示しています。 効率的なワークフロー管理のために、DAG、タスク、演算子などのコアエアフローの概念...AI 2025-04-12に投稿されました















中国語を勉強する
- 1 「歩く」は中国語で何と言いますか? 走路 中国語の発音、走路 中国語学習
- 2 「飛行機に乗る」は中国語で何と言いますか? 坐飞机 中国語の発音、坐飞机 中国語学習
- 3 「電車に乗る」は中国語で何と言いますか? 坐火车 中国語の発音、坐火车 中国語学習
- 4 「バスに乗る」は中国語で何と言いますか? 坐车 中国語の発音、坐车 中国語学習
- 5 中国語でドライブは何と言うでしょう? 开车 中国語の発音、开车 中国語学習
- 6 水泳は中国語で何と言うでしょう? 游泳 中国語の発音、游泳 中国語学習
- 7 中国語で自転車に乗るってなんて言うの? 骑自行车 中国語の発音、骑自行车 中国語学習
- 8 中国語で挨拶はなんて言うの? 你好中国語の発音、你好中国語学習
- 9 中国語でありがとうってなんて言うの? 谢谢中国語の発音、谢谢中国語学習
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









