 Page de garde > La programmation > Optimisation du web scraping : scraping des données d'authentification à l'aide de JSDOM
Page de garde > La programmation > Optimisation du web scraping : scraping des données d'authentification à l'aide de JSDOM
Optimisation du web scraping : scraping des données d'authentification à l'aide de JSDOM
 Parcourir:351
Parcourir:351
En tant que développeurs de scraping, nous devons parfois extraire des données d'authentification telles que des clés temporaires pour effectuer nos tâches. Toutefois, ce n’est pas aussi simple que cela. Habituellement, il s'agit de requêtes réseau HTML ou XHR, mais parfois, les données d'authentification sont calculées. Dans ce cas, nous pouvons soit procéder à une ingénierie inverse du calcul, ce qui prend beaucoup de temps pour désobscurcir les scripts, soit exécuter le JavaScript qui le calcule. Normalement, nous utilisons un navigateur, mais cela coûte cher. Crawlee prend en charge l'exécution de Browser Scraper et de Cheerio Scraper en parallèle, mais cela est très complexe et coûteux en termes d'utilisation des ressources de calcul. JSDOM nous aide à exécuter du JavaScript de page avec moins de ressources qu'un navigateur et légèrement plus élevé que Cheerio.
Cet article discutera d'une nouvelle approche que nous utilisons dans l'un de nos acteurs pour obtenir les données d'authentification du centre de création de publicités TikTok générées par les applications Web du navigateur sans exécuter réellement le navigateur mais à la place de celui-ci, en utilisant JSDOM.
Analyser le site Web
Lorsque vous visitez cette URL :
https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pc/en
Vous verrez une liste de hashtags avec leur classement en direct, le nombre de publications qu'ils ont publiées, un tableau de tendances, des créateurs et des analyses. Vous pouvez également remarquer que nous pouvons filtrer le secteur, définir la période de temps et utiliser une case à cocher pour filtrer si la tendance est nouvelle dans le top 100 ou non.
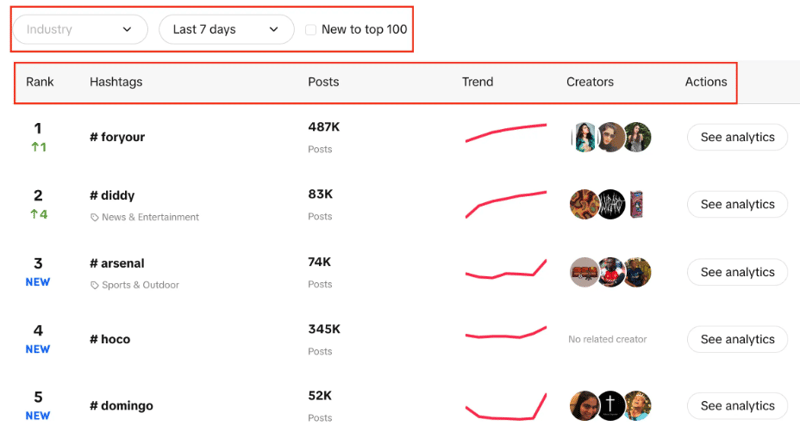
Notre objectif ici est d'extraire les 100 meilleurs hashtags de la liste avec les filtres donnés.
Les deux approches possibles consistent à utiliser CheerioCrawler, et la seconde sera le scraping basé sur le navigateur. Cheerio donne des résultats plus rapidement mais ne fonctionne pas avec les sites Web rendus en JavaScript.
Cheerio n'est pas la meilleure option ici car le Creative Center est une application Web et la source de données est une API, nous ne pouvons donc obtenir que les hashtags initialement présents dans la structure HTML, mais pas chacun des 100 dont nous avons besoin.
La deuxième approche peut consister à utiliser des bibliothèques comme Puppeteer, Playwright, etc., pour effectuer du scraping basé sur le navigateur et à utiliser l'automatisation pour scraper tous les hashtags, mais avec les expériences précédentes, cela prend beaucoup de temps pour une si petite tâche.
Vient maintenant la nouvelle approche que nous avons développée pour rendre ce processus bien meilleur que celui basé sur un navigateur et très proche de l'exploration basée sur CheerioCrawler.
Approche JSDOM
Avant d'approfondir cette approche, je voudrais remercier Alexey Udovydchenko, ingénieur en automatisation Web chez Apify, pour avoir développé cette approche. Félicitations à lui !
Dans cette approche, nous allons effectuer des appels API vers https://ads.tiktok.com/creative_radar_api/v1/popular_trend/hashtag/list pour obtenir les données requises.
Avant d'appeler cette API, nous aurons besoin de quelques en-têtes requis (données d'authentification), nous allons donc d'abord appeler https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad /fr.
Nous allons commencer cette approche en créant une fonction qui créera l'URL de l'appel API pour nous, passera l'appel et obtiendra les données.
export const createStartUrls = (input) => {
const {
days = '7',
country = '',
resultsLimit = 100,
industry = '',
isNewToTop100,
} = input;
const filterBy = isNewToTop100 ? 'new_on_board' : '';
return [
{
url: `https://ads.tiktok.com/creative_radar_api/v1/popular_trend/hashtag/list?page=1&limit=50&period=${days}&country_code=${country}&filter_by=${filterBy}&sort_by=popular&industry_id=${industry}`,
headers: {
// required headers
},
userData: { resultsLimit },
},
];
};
Dans la fonction ci-dessus, nous créons l'URL de démarrage pour l'appel d'API qui inclut divers paramètres comme nous l'avons mentionné précédemment. Après avoir créé l'URL en fonction des paramètres, elle appellera creative_radar_api et récupérera tous les résultats.
Mais cela ne fonctionnera pas tant que nous n'aurons pas les en-têtes. Créons donc une fonction qui créera d'abord une session en utilisant sessionPool et proxyConfiguration.
export const createSessionFunction = async (
sessionPool,
proxyConfiguration,
) => {
const proxyUrl = await proxyConfiguration.newUrl(Math.random().toString());
const url =
'https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad/en';
// need url with data to generate token
const response = await gotScraping({ url, proxyUrl });
const headers = await getApiUrlWithVerificationToken(
response.body.toString(),
url,
);
if (!headers) {
throw new Error(`Token generation blocked`);
}
log.info(`Generated API verification headers`, Object.values(headers));
return new Session({
userData: {
headers,
},
sessionPool,
});
};
Dans cette fonction, l'objectif principal est d'appeler https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad/en et d'obtenir des en-têtes en retour. Pour obtenir les en-têtes, nous utilisons la fonction getApiUrlWithVerificationToken.
Avant de continuer, je tiens à mentionner que Crawlee prend en charge nativement JSDOM à l'aide du JSDOM Crawler. Il fournit un cadre pour l'exploration parallèle de pages Web à l'aide de requêtes HTTP simples et de l'implémentation du DOM jsdom. Il utilise des requêtes HTTP brutes pour télécharger des pages Web, il est très rapide et efficace sur la bande passante des données.
Voyons comment nous allons créer la fonction getApiUrlWithVerificationToken :
const getApiUrlWithVerificationToken = async (body, url) => {
log.info(`Getting API session`);
const virtualConsole = new VirtualConsole();
const { window } = new JSDOM(body, {
url,
contentType: 'text/html',
runScripts: 'dangerously',
resources: 'usable' || new CustomResourceLoader(),
// ^ 'usable' faster than custom and works without canvas
pretendToBeVisual: false,
virtualConsole,
});
virtualConsole.on('error', () => {
// ignore errors cause by fake XMLHttpRequest
});
const apiHeaderKeys = ['anonymous-user-id', 'timestamp', 'user-sign'];
const apiValues = {};
let retries = 10;
// api calls made outside of fetch, hack below is to get URL without actual call
window.XMLHttpRequest.prototype.setRequestHeader = (name, value) => {
if (apiHeaderKeys.includes(name)) {
apiValues[name] = value;
}
if (Object.values(apiValues).length === apiHeaderKeys.length) {
retries = 0;
}
};
window.XMLHttpRequest.prototype.open = (method, urlToOpen) => {
if (
['static', 'scontent'].find((x) =>
urlToOpen.startsWith(`https://${x}`),
)
)
log.debug('urlToOpen', urlToOpen);
};
do {
await sleep(4000);
retries--;
} while (retries > 0);
await window.close();
return apiValues;
};
Dans cette fonction, nous créons une console virtuelle qui utilise CustomResourceLoader pour exécuter le processus en arrière-plan et remplacer le navigateur par JSDOM.
Pour cet exemple particulier, nous avons besoin de trois en-têtes obligatoires pour effectuer l'appel d'API, à savoir l'identifiant d'utilisateur anonyme, l'horodatage et la signature de l'utilisateur.
En utilisant XMLHttpRequest.prototype.setRequestHeader, nous vérifions si les en-têtes mentionnés sont dans la réponse ou non, si oui, nous prenons la valeur de ces en-têtes et répétons les tentatives jusqu'à ce que nous obtenions tous les en-têtes.
Ensuite, la partie la plus importante est que nous utilisons XMLHttpRequest.prototype.open pour extraire les données d'authentification et passer des appels sans réellement utiliser de navigateurs ni exposer l'activité du robot.
À la fin de createSessionFunction, il renvoie une session avec les en-têtes requis.
Venons-en maintenant à notre code principal, nous utiliserons CheerioCrawler et prenavigationHooks pour injecter les en-têtes que nous avons obtenus de la fonction précédente dans requestHandler.
const crawler = new CheerioCrawler({
sessionPoolOptions: {
maxPoolSize: 1,
createSessionFunction: async (sessionPool) =>
createSessionFunction(sessionPool, proxyConfiguration),
},
preNavigationHooks: [
(crawlingContext) => {
const { request, session } = crawlingContext;
request.headers = {
...request.headers,
...session.userData?.headers,
};
},
],
proxyConfiguration,
});
Enfin, dans le gestionnaire de requêtes, nous effectuons l'appel en utilisant les en-têtes et nous assurons combien d'appels sont nécessaires pour récupérer toute la pagination de gestion des données.
async requestHandler(context) {
const { log, request, json } = context;
const { userData } = request;
const { itemsCounter = 0, resultsLimit = 0 } = userData;
if (!json.data) {
throw new Error('BLOCKED');
}
const { data } = json;
const items = data.list;
const counter = itemsCounter items.length;
const dataItems = items.slice(
0,
resultsLimit && counter > resultsLimit
? resultsLimit - itemsCounter
: undefined,
);
await context.pushData(dataItems);
const {
pagination: { page, total },
} = data;
log.info(
`Scraped ${dataItems.length} results out of ${total} from search page ${page}`,
);
const isResultsLimitNotReached =
counter
Une chose importante à noter ici est que nous créons ce code de manière à pouvoir effectuer n'importe quel nombre d'appels API.
Dans cet exemple particulier, nous venons de faire une seule demande et une seule session, mais vous pouvez en faire plus si vous en avez besoin. Lorsque le premier appel API sera terminé, le deuxième appel API sera créé. Encore une fois, vous pouvez passer plus d'appels si nécessaire, mais nous nous sommes arrêtés à deux.
Pour rendre les choses plus claires, voici à quoi ressemble le flux de code :
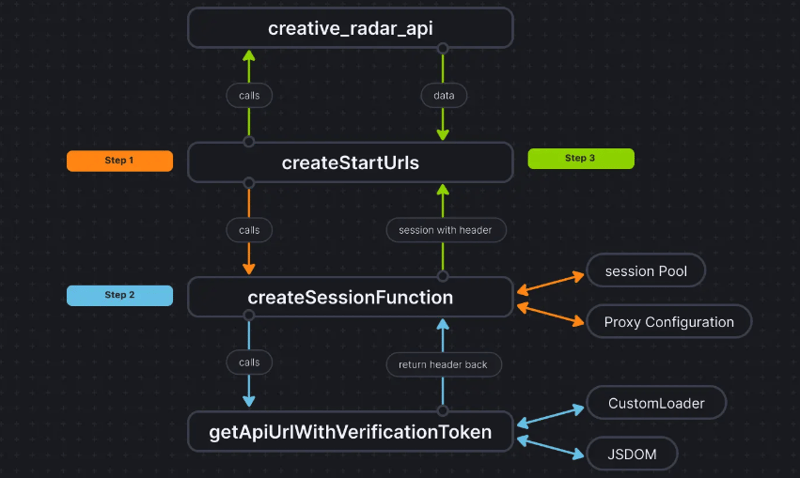
Conclusion
Cette approche nous aide à trouver une troisième façon d'extraire les données d'authentification sans réellement utiliser de navigateur et de transmettre les données à CheerioCrawler. Cela améliore considérablement les performances et réduit les besoins en RAM de 50 %, et bien que les performances de scraping basées sur le navigateur soient dix fois plus lentes que celles de Cheerio pur, JSDOM le fait seulement 3 à 4 fois plus lentement, ce qui le rend 2 à 3 fois plus rapide que celui du navigateur. basé sur le grattage.
La base de code du projet est déjà téléchargée ici. Le code est écrit sous la forme d'un acteur Apify ; vous pouvez en savoir plus ici, mais vous pouvez également l'exécuter sans utiliser le SDK Apify.
Si vous avez des doutes ou des questions sur cette approche, contactez-nous sur notre serveur Discord.
-
 Résoudre l'erreur \\ "Erreur de valeur de chaîne \\" Exception lorsque MySQL inserte emojiRésolution de la valeur de chaîne incorrecte Exception lors de l'insertion d'Emoji lorsque vous essayez d'insérer une chaîne contena...La programmation Publié le 2025-05-23
Résoudre l'erreur \\ "Erreur de valeur de chaîne \\" Exception lorsque MySQL inserte emojiRésolution de la valeur de chaîne incorrecte Exception lors de l'insertion d'Emoji lorsque vous essayez d'insérer une chaîne contena...La programmation Publié le 2025-05-23 -
Comment télécharger des fichiers avec des paramètres supplémentaires à l'aide de java.net.urlconnection et de codage multipart / formulaire de formulaire?Téléchargement des fichiers avec des demandes http pour télécharger des fichiers sur un serveur http tout en soumettant des paramètres supplém...La programmation Publié le 2025-05-23
-
Les paramètres de modèle dans la fonction consévale C ++ 20 peuvent-ils dépendre des paramètres de fonction?Fonctions et paramètres de modèle constitutifs dépendants des arguments de fonction En C Compile-Time. C 20 Fonctions Consévales C 20 in...La programmation Publié le 2025-05-23
-
Quand une application Web GO ferme-t-elle la connexion de la base de données?Gestion des connexions de bases de données dans les applications Web Go Dans les applications Web simples GO qui utilisent des bases de données ...La programmation Publié le 2025-05-23
-
Async void vs tâche asynchrone dans ASP.NET: Pourquoi la méthode asynchrone void lance-t-elle parfois des exceptions?Comprendre la distinction entre la tâche asynchrone void et asynchrone dans asp.net dans les applications ASP.net, le programme asynchronique ...La programmation Publié le 2025-05-23
-
Puis-je migrer mon cryptage de McRypt à OpenSSL et décrypter les données cryptées McRypt à l'aide d'OpenSSL?Mise à niveau de ma bibliothèque de chiffrement de McRypt à OpenSSL Puis-je mettre à niveau ma bibliothèque de cryptage à partir de McRypt à O...La programmation Publié le 2025-05-23
-
Comment convertir efficacement les fuseaux horaires en PHP?Conversion efficace du fuseau horaire en php Dans PHP, la gestion des fuseaux horaires peut être une tâche simple. Ce guide fournira une méthode...La programmation Publié le 2025-05-23
-
Comment implémenter des événements personnalisés en utilisant le modèle d'observateur en Java?Création d'événements personnalisés dans java Les événements personnalisés sont indispensables dans de nombreux scénarios de programmation, ...La programmation Publié le 2025-05-23
-
Java autorise-t-il plusieurs types de retour: un regard plus approfondi sur les méthodes génériques?Plusieurs types de retour en java: une idée fausse dévoilée dans le domaine de la programmation java, une signature de méthode particulière pe...La programmation Publié le 2025-05-23
-
Pourquoi DateTime :: Modify de PHP («+ 1 mois») produit-il des résultats inattendus?Modification des mois avec PHP DateTime: Découvrir le comportement prévu Lorsque vous travaillez avec la classe DateTime de Php, l'ajout o...La programmation Publié le 2025-05-23
-
Comment créer une animation CSS à gauche à gauche en douceur pour une div dans son conteneur?Animation CSS générique pour le mouvement gauche-droit Dans cet article, nous explorerons la création d'une animation CSS générique pour d...La programmation Publié le 2025-05-23
-
Comment détecter efficacement les tableaux vides en PHP?Vérification du vide du tableau en php Un tableau vide peut être déterminé en php via diverses approches. Si le besoin est de vérifier la prés...La programmation Publié le 2025-05-23
-
Pouvez-vous utiliser CSS pour colorer la sortie de la console dans Chrome et Firefox?Affichage des couleurs dans la console javascrip Messages? Réponse Oui, il est possible d'utiliser CSS pour ajouter des couleurs aux me...La programmation Publié le 2025-05-23
-
Quelle méthode est la plus efficace pour la détection ponctuelle en polygone: traçage des rayons ou path.contains_points de Matplotlib \?détection efficace de ponctuel en polygone dans python déterminer si un point se trouve dans un polygone est une tâche fréquente en géométrie de...La programmation Publié le 2025-05-23
-
Comment capturer et diffuser Stdout en temps réel pour l'exécution de la commande chatbot?Capturant stdout en temps réel à partir de l'exécution de commandes dans le domaine de l'élaboration de chatbots capables d'exécut...La programmation Publié le 2025-05-23















Étudier le chinois
- 1 Comment dit-on « marcher » en chinois ? 走路 Prononciation chinoise, 走路 Apprentissage du chinois
- 2 Comment dit-on « prendre l’avion » en chinois ? 坐飞机 Prononciation chinoise, 坐飞机 Apprentissage du chinois
- 3 Comment dit-on « prendre un train » en chinois ? 坐火车 Prononciation chinoise, 坐火车 Apprentissage du chinois
- 4 Comment dit-on « prendre un bus » en chinois ? 坐车 Prononciation chinoise, 坐车 Apprentissage du chinois
- 5 Comment dire conduire en chinois? 开车 Prononciation chinoise, 开车 Apprentissage du chinois
- 6 Comment dit-on nager en chinois ? 游泳 Prononciation chinoise, 游泳 Apprentissage du chinois
- 7 Comment dit-on faire du vélo en chinois ? 骑自行车 Prononciation chinoise, 骑自行车 Apprentissage du chinois
- 8 Comment dit-on bonjour en chinois ? 你好Prononciation chinoise, 你好Apprentissage du chinois
- 9 Comment dit-on merci en chinois ? 谢谢Prononciation chinoise, 谢谢Apprentissage du chinois
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









