 Página delantera > Programación > Cómo la optimización de la comparación hace que la clasificación de Python sea más rápida
Página delantera > Programación > Cómo la optimización de la comparación hace que la clasificación de Python sea más rápida
Cómo la optimización de la comparación hace que la clasificación de Python sea más rápida
 Navegar:225
Navegar:225
En este texto los términos Python y CPython, que es la implementación de referencia del lenguaje, se usan indistintamente. Este artículo aborda específicamente CPython y no se refiere a ninguna otra implementación de Python.
Python es un hermoso lenguaje que permite a un programador expresar sus ideas en términos simples dejando la complejidad de la implementación real detrás de escena.
Una de las cosas que abstrae es la clasificación.
Puedes encontrar fácilmente la respuesta a la pregunta "¿cómo se implementa la clasificación en Python?" que casi siempre responde a otra pregunta: "¿Qué algoritmo de clasificación utiliza Python?".
Sin embargo, esto a menudo deja atrás algunos detalles de implementación interesantes.
Hay un detalle de implementación que creo que no se analiza lo suficiente, a pesar de que se introdujo hace más de siete años en Python 3.7:
sorted() y list.sort() se han optimizado para que los casos comunes sean entre un 40 % y un 75 % más rápidos. (Aportado por Elliot Gorokhovsky en bpo-28685.)
Pero antes de comenzar...
Breve reintroducción a la clasificación en Python
Cuando necesitas ordenar una lista en Python, tienes dos opciones:
- Un método de lista: list.sort(*, key=None, reverse=False), que ordena la lista dada in situ
- Una función incorporada: sorted(iterable, /, *, key=None, reverse= False), que devuelve una lista ordenada sin modificar su argumento
Si necesita ordenar cualquier otro iterable integrado, solo puede usar ordenado independientemente del tipo de iterable o generador pasado como parámetro.
sorted siempre devuelve una lista porque usa list.sort internamente.
Aquí hay un equivalente aproximado de la implementación C ordenada de CPython reescrita en Python puro:
def sorted(iterable: Iterable[Any], key=None, reverse=False):
new_list = list(iterable)
new_list.sort(key=key, reverse=reverse)
return new_list
Sí, es así de simple.
Cómo Python agiliza la clasificación
Como dice la documentación interna de Python para la clasificación:
A veces es posible sustituir comparaciones específicas de tipo más rápidas por el PyObject_RichCompareBool genérico, más lento
Y en resumen esta optimización se puede describir de la siguiente manera:
Cuando una lista es homogénea, Python usa función de comparación específica del tipo
¿Qué es una lista homogénea?
Una lista homogénea es una lista que contiene elementos de un solo tipo.
Por ejemplo:
homogeneous = [1, 2, 3, 4]
Por otro lado, esta no es una lista homogénea:
heterogeneous = [1, "2", (3, ), {'4': 4}]
Curiosamente, el tutorial oficial de Python dice:
Las listas son mutables y sus elementos son generalmente homogéneos y se accede a ellos iterando sobre la lista
Una nota al margen sobre las tuplas
Ese mismo tutorial dice:
Las tuplas son inmutables y normalmente contienen una secuencia heterogénea de elementos
Así que si alguna vez te preguntas cuándo usar una tupla o una lista, aquí tienes una regla general:
si los elementos son del mismo tipo, use una lista; de lo contrario, use una tupla
Espera, ¿y qué pasa con las matrices?
Python implementa un objeto contenedor de matriz homogéneo para valores numéricos.
Sin embargo, a partir de Python 3.12, las matrices no implementan su propio método de clasificación.
La única forma de ordenarlos es usando sorted, que crea internamente una lista a partir de la matriz, borrando cualquier información relacionada con el tipo en el proceso.
¿Por qué es útil utilizar la función de comparación de tipos específicos?
Las comparaciones en Python son costosas, porque Python realiza varias comprobaciones antes de realizar cualquier comparación real.
Aquí hay una explicación simplificada de lo que sucede cuando comparas dos valores en Python:
- Python verifica que los valores pasados a la función de comparación no sean NULL
- Si los valores son de diferentes tipos, pero el operando derecho es un subtipo del izquierdo, Python usa la función de comparación del operando derecho, pero al revés (por ejemplo, usará )
- Si los valores son del mismo tipo, o de diferentes tipos pero ninguno es un subtipo del otro:
- Python probará primero la función de comparación del operando izquierdo
- Si eso falla, intentará la función de comparación del operando correcto, pero al revés.
- Si eso también falla, y la comparación es para igualdad o desigualdad, devolverá una comparación de identidad (Verdadero para valores que se refieren al mismo objeto en la memoria)
- De lo contrario, genera TypeError
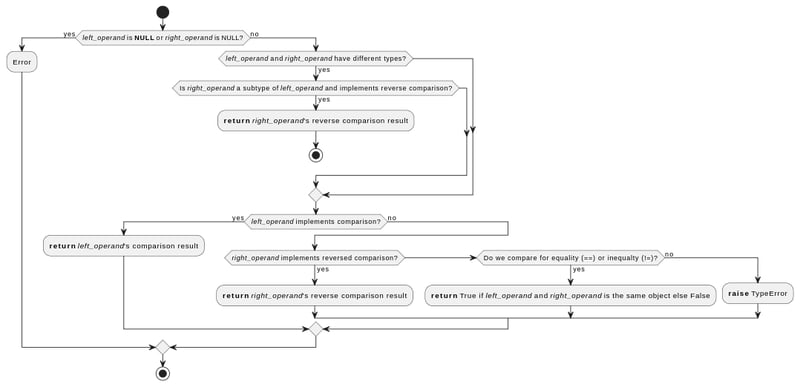
Además de esto, las funciones de comparación propias de cada tipo implementan comprobaciones adicionales.
Por ejemplo, al comparar cadenas, Python verificará si los caracteres de la cadena ocupan más de un byte de memoria, y la comparación flotante comparará un par de flotantes y un flotante y un int de manera diferente.
Puede encontrar una explicación y un diagrama más detallados aquí: Agregar optimizaciones de clasificación basadas en datos a CPython
Antes de que se introdujera esta optimización, Python tenía que ejecutar todas estas comprobaciones específicas y no específicas de tipo cada vez que se comparaban dos valores durante la clasificación.
Verificación anticipada de los tipos de elementos de la lista
No existe una forma mágica de saber si todos los elementos de una lista son del mismo tipo que no sea iterar sobre la lista y verificar cada elemento.
Python hace casi exactamente eso: verificar los tipos de claves de clasificación generadas por la función clave pasada a list.sort o ordenada como parámetro
Construyendo una lista de claves
Si se proporciona una función clave, Python la usa para construir una lista de claves; de lo contrario, usa los valores propios de la lista como claves de clasificación.
De manera muy simplificada, la construcción de claves se puede expresar como el siguiente código Python.
if key is None:
keys = list_items
else:
keys = [key(list_item) for list_item in list_item]
Tenga en cuenta que las claves utilizadas internamente en CPython son una matriz C de referencias de objetos CPython, y no una lista de Python
Una vez construidas las claves, Python verifica sus tipos.
Comprobando el tipo de clave
Al verificar los tipos de claves, el algoritmo de clasificación de Python intenta determinar si todos los elementos en la matriz de claves son str, int, float o tuple, o simplemente del mismo tipo, con algunas restricciones para los tipos base.
Vale la pena señalar que verificar los tipos de claves agrega algo de trabajo adicional por adelantado. Python hace esto porque generalmente vale la pena al hacer que la clasificación sea más rápida, especialmente para listas más largas.
restricciones internas
int debería no ser un bignum
Prácticamente esto significa que para que esta optimización funcione, el número entero debe ser menor que 2^30 - 1 (esto puede variar dependiendo de la plataforma)
Como nota al margen, aquí hay un excelente artículo que explica cómo Python maneja los enteros grandes: # ¿Cómo implementa Python los enteros súper largos?
restricciones str
Todos los caracteres de una cadena deben ocupar menos de 1 byte de memoria, lo que significa que deben representarse mediante valores enteros en el rango de 0-255
En la práctica, esto significa que las cadenas deben constar únicamente de caracteres latinos, espacios y algunos caracteres especiales que se encuentran en la tabla ASCII.
restricciones de flotación
No hay restricciones para los flotadores para que esta optimización funcione.
restricciones de tupla
- Solo se marca el tipo del primer elemento
- Este elemento en sí no debería ser una tupla en sí mismo
- Si todas las tuplas comparten el mismo tipo para su primer elemento, se les aplica la optimización de comparación
- Todos los demás elementos se comparan como de costumbre
¿Cómo puedo aplicar este conocimiento?
En primer lugar, ¿no es fascinante saberlo?
En segundo lugar, mencionar este conocimiento podría ser un buen toque en una entrevista para un desarrollador de Python.
En cuanto al desarrollo del código real, comprender esta optimización puede ayudarle a mejorar el rendimiento de clasificación.
Optimice seleccionando sabiamente el tipo de valores
Según el punto de referencia en el PR que introdujo esta optimización, ordenar una lista que consta solo de flotantes en lugar de una lista de flotantes con incluso un solo número entero al final es casi el doble de rápido.
Entonces, cuando llegue el momento de optimizar, transformar una lista como esta
floats_and_int = [1.0, -1.0, -0.5, 3]
En una lista similar a esta
just_floats = [1.0, -1.0, -0.5, 3.0] # note that 3.0 is a float now
podría mejorar el rendimiento.
Optimice mediante el uso de claves para listas de objetos
Si bien la optimización de clasificación de Python funciona bien con tipos integrados, es importante comprender cómo interactúa con clases personalizadas.
Al ordenar objetos de clases personalizadas, Python se basa en los métodos de comparación que usted define, como __lt__ (menor que) o __gt__ (mayor que).
Sin embargo, la optimización específica del tipo no se aplica a las clases personalizadas.
Python siempre utilizará el método de comparación general para estos objetos.
Aquí tienes un ejemplo:
class MyClass:
def __init__(self, value):
self.value = value
def __lt__(self, other):
return self.value
En este caso, Python utilizará el método __lt__ para realizar comparaciones, pero no se beneficiará de la optimización específica del tipo. La clasificación seguirá funcionando correctamente, pero es posible que no sea tan rápida como la clasificación de tipos integrados.
Si el rendimiento es fundamental al ordenar objetos personalizados, considere usar una función clave que devuelva un tipo integrado:
sorted_list = sorted(my_list, key=lambda x: x.value)
Epílogo
La optimización prematura, especialmente en Python, es mala.
No debes diseñar toda tu aplicación en torno a optimizaciones específicas en CPython, pero es bueno estar al tanto de estas optimizaciones: conocer bien tus herramientas es una forma de convertirte en un desarrollador más capacitado.
Tener en cuenta optimizaciones como estas le permite aprovecharlas cuando la situación lo requiere, especialmente cuando el rendimiento se vuelve crítico:
Considere un escenario en el que su clasificación se base en marcas de tiempo: usar una lista homogénea de números enteros (marcas de tiempo de Unix) en lugar de objetos de fecha y hora podría aprovechar esta optimización de manera efectiva.
Sin embargo, es fundamental recordar que la legibilidad y el mantenimiento del código deben tener prioridad sobre dichas optimizaciones.
Si bien es importante conocer estos detalles de bajo nivel, es igualmente importante apreciar las abstracciones de alto nivel de Python que lo convierten en un lenguaje tan productivo.
Python es un lenguaje asombroso y explorar sus profundidades puede ayudarte a comprenderlo mejor y convertirte en un mejor programador de Python.
-
 ¿Cómo puedo seleccionar programáticamente todo el texto dentro de un DIV en el clic del mouse?seleccionando el texto DIV en el mouse clic pregunta Dado un elemento DIV con contenido de texto, ¿cómo puede el usuario seleccionar programát...Programación Publicado el 2025-07-15
¿Cómo puedo seleccionar programáticamente todo el texto dentro de un DIV en el clic del mouse?seleccionando el texto DIV en el mouse clic pregunta Dado un elemento DIV con contenido de texto, ¿cómo puede el usuario seleccionar programát...Programación Publicado el 2025-07-15 -
¿Cómo puedo mantener la representación de celda JTable personalizada después de la edición de la celda?manteniendo la representación de la celda JTable después de la edición de celda en una jtable, implementar capacidades de representación y edi...Programación Publicado el 2025-07-15
-
Método de corriente efectiva para cadenas de Java que no son vacías y no son nulasCompre 1.6 y más tarde, el método isEtimty () proporciona una forma concisa de verificar el vacío: if (str! = Null &&! Str.isEmEmEmEnty () o...Programación Publicado el 2025-07-15
-
¿Cómo implementar una función hash genérica para tuplas en colecciones desordenadas?Función hash genérica para tuplas en colecciones no ordenadas los contenedores std :: unordened_map y std :: unordened_set proporcionan una mi...Programación Publicado el 2025-07-15
-
Razones para que CodeIgniter se conecte a la base de datos MySQL después de cambiar a MySQLINo se puede conectar a la base de datos mySQL: Mensaje de error de solución de problemas al intentar cambiar desde el controlador mySQL al con...Programación Publicado el 2025-07-15
-
¿Cómo usar correctamente las consultas como los parámetros PDO?usando consultas similares en pdo al intentar implementar una consulta similar en PDO, puede encontrar problemas como el que se describe en la...Programación Publicado el 2025-07-15
-
¿Cómo pasar punteros exclusivos como función o parámetros de constructor en C ++?Gestión de punteros únicos como parámetros en constructores y funciones únicos indicadores ( unique_ptr ) para que los principios de la propieda...Programación Publicado el 2025-07-15
-
¿Cuándo usar "Prueba" en lugar de "IF" para detectar valores variables en Python?usando "Prueba" vs. "Si" para probar el valor variable en Python en Python, hay situaciones en las que es posible que necesi...Programación Publicado el 2025-07-15
-
El error del compilador "usr/bin/ld: no se puede encontrar -l" soluciónError encontrado: "usr/bin/ld: no puedo encontrar -l " -l usr/bin/ld: cannot find -l<nameOfTheLibrary> agregando rutas de ...Programación Publicado el 2025-07-15
-
Método XML de análisis de PHP simple con colon de espacio de nombresanalizando xml con las colons de espacio de nombres en php simplexml encuentra dificultades al analizar XML que contiene etiquetas con colons,...Programación Publicado el 2025-07-15
-
¿Cuáles fueron las restricciones al usar Current_Timestamp con columnas de marca de tiempo en MySQL antes de la versión 5.6.5?en las columnas de la marca de tiempo con cursion_timestamp en predeterminado o en las cláusulas de actualización en las versiones mySql antes de ...Programación Publicado el 2025-07-15
-
¿Java permite múltiples tipos de devolución: una mirada más cercana a los métodos genéricos?múltiples tipos de retorno en java: una concepción errónea indicada en el reino de la programación de java, una firma de método de método pued...Programación Publicado el 2025-07-15
-
La diferencia entre el procesamiento de sobrecarga de la función PHP y C ++PHP Función sobrecarga: desentrañar el enigma desde una perspectiva C como un desarrollador de C experimentado en el ámbito de PHP, puede encont...Programación Publicado el 2025-07-15
-
Python forma eficiente de eliminar las etiquetas HTML del textoeliminando las etiquetas HTML en Python para una representación textual prístina manipular las respuestas HTML a menudo implica extraer conten...Programación Publicado el 2025-07-15
-
Consejos para encontrar la posición del elemento en Java ArrayRecuperando la posición del elemento en las matrices Java dentro de la clase de matrices de Java, no hay un método directo de "índice de ...Programación Publicado el 2025-07-15















Estudiar chino
- 1 ¿Cómo se dice "caminar" en chino? 走路 pronunciación china, 走路 aprendizaje chino
- 2 ¿Cómo se dice "tomar un avión" en chino? 坐飞机 pronunciación china, 坐飞机 aprendizaje chino
- 3 ¿Cómo se dice "tomar un tren" en chino? 坐火车 pronunciación china, 坐火车 aprendizaje chino
- 4 ¿Cómo se dice "tomar un autobús" en chino? 坐车 pronunciación china, 坐车 aprendizaje chino
- 5 ¿Cómo se dice conducir en chino? 开车 pronunciación china, 开车 aprendizaje chino
- 6 ¿Cómo se dice nadar en chino? 游泳 pronunciación china, 游泳 aprendizaje chino
- 7 ¿Cómo se dice andar en bicicleta en chino? 骑自行车 pronunciación china, 骑自行车 aprendizaje chino
- 8 ¿Cómo se dice hola en chino? 你好Pronunciación china, 你好Aprendizaje chino
- 9 ¿Cómo se dice gracias en chino? 谢谢Pronunciación china, 谢谢Aprendizaje chino
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









