
Mysql数据库索引初学者详解
 浏览:460
浏览:460
Core Concepts
- Primary Key Index / Secondary Index
- Clustered Index / Non-Clustered Index
- Table Lookup / Index Covering
- Index Pushdown
- Composite Index / Leftmost Prefix Matching
- Prefix Index
- Explain
1. [Index Definition]
1. Index Definition
Besides the data itself, the database system also maintains data structures that satisfy specific search algorithms. These structures reference (point to) the data in a certain way, allowing advanced search algorithms to be implemented on them. These data structures are indexes.
2. Data Structures of Indexes
- B-tree / B tree (MySQL's InnoDB engine uses B tree as the default index structure)
- HASH table
- Sorted array
3. Why Choose B Tree Over B Tree
- B-tree structure: Records are stored in the tree nodes.
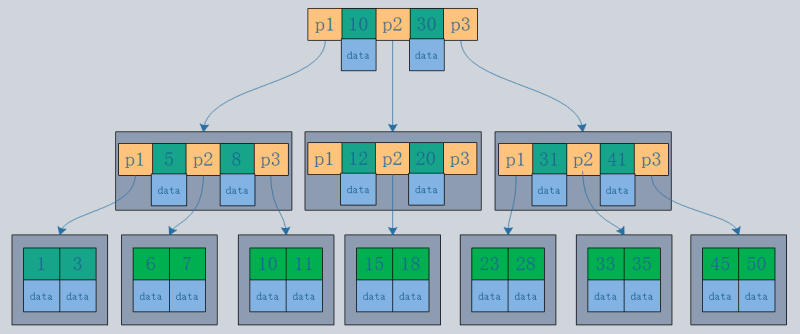
- B tree structure: Records are stored only in the leaf nodes of the tree.
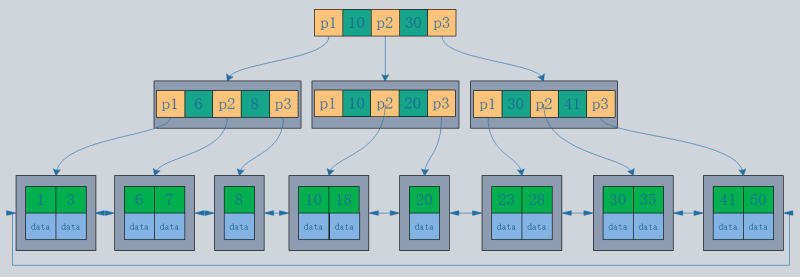
- Assuming a data size of 1KB and an index size of 16B, with the database using disk data pages, and a default disk page size of 16K, the same three I/O operations will yield:
B-tree can fetch 16*16*16=4096 records.
B tree can fetch 1000*1000*1000=1 billion records.
2. [Index Types]
1. Primary Key Index and Secondary Index
- Primary Key Index: The leaf nodes of the index are data rows.
- Secondary Index: The leaf nodes of the index are KEY fields plus primary key index. Therefore, when querying through a secondary index, it first finds the primary key value, and then InnoDB finds the corresponding data block through the primary key index.
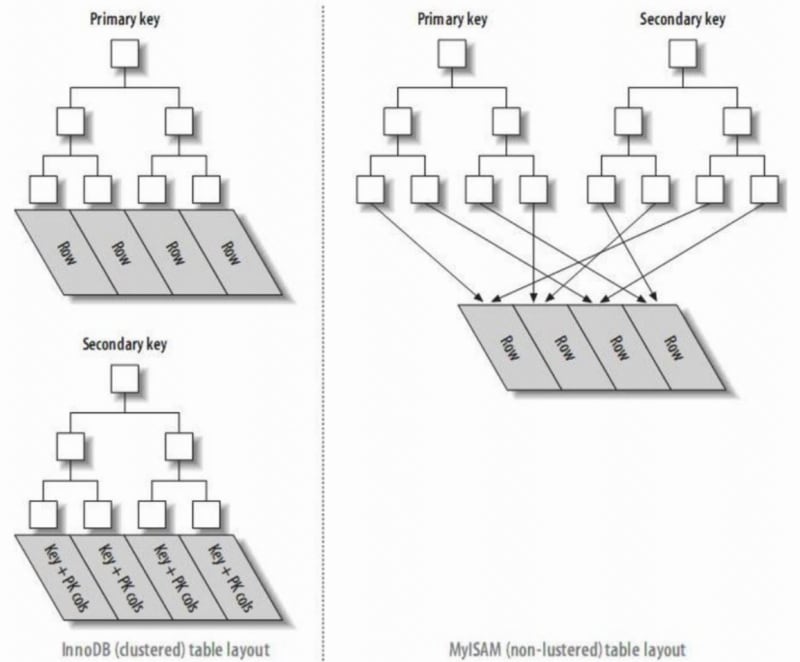
- In InnoDB, the primary index file directly stores the data row, called clustered index, while secondary indexes point to the primary key reference.
- In MyISAM, both primary and secondary indexes point to physical rows (disk positions).
2. Clustered Index and Non-Clustered Index
- A clustered index reorganizes the actual data on the disk to be sorted by one or more specified column values. The characteristic is that the storage order of the data and the index order are consistent. Generally, the primary key will default to creating a clustered index, and a table only allows one clustered index (reason: data can only be stored in one order). As shown in the image, InnoDB's primary and secondary indexes are clustered indexes.
- Compared to the leaf nodes of a clustered index being data records, the leaf nodes of a non-clustered index are pointers to the data records. The biggest difference is that the order of data records does not match the index order.
3. Advantages and Disadvantages of Clustered Index
- Advantage: When querying entries by primary key, it does not need to perform a table lookup (data is under the primary key node).
- Disadvantage: Frequent page splits can occur with irregular data insertion.
3. [Extended Index Concepts]
1. Table Lookup
The concept of table lookup involves the difference between primary key index and non-primary key index queries.
- If the query is select * from T where ID=500, a primary key query only needs to search the ID tree.
- If the query is select * from T where k=5, a non-primary key index query needs to first search the k index tree to get the ID value of 500, then search the ID index tree again.
- The process of moving from the non-primary key index back to the primary key index is called table lookup.
Queries based on non-primary key indexes require scanning an additional index tree. Therefore, we should try to use primary key queries in applications. From the perspective of storage space, since the leaf nodes of the non-primary key index tree store primary key values, it is advisable to keep the primary key fields as short as possible. This way, the leaf nodes of the non-primary key index tree are smaller, and the non-primary key index occupies less space. Generally, it is recommended to create an auto-increment primary key to minimize the space occupied by non-primary key indexes.
2. Index Covering
- If a WHERE clause condition is a non-primary key index, the query will first locate the primary key index through the non-primary key index (the primary key is located at the leaf nodes of the non-primary key index search tree), and then locate the query content through the primary key index. In this process, moving back to the primary key index tree is called table lookup.
- However, when our query content is the primary key value, we can directly provide the query result without table lookup. In other words, the non-primary key index has already "covered" our query requirement in this query, hence it is called a covering index.
- A covering index can directly obtain query results from the auxiliary index without table lookup to the primary index, thereby reducing the number of searches (not needing to move from the auxiliary index tree to the clustered index tree) or reducing IO operations (the auxiliary index tree can load more nodes from the disk at once), thereby improving performance.
3. Composite Index
A composite index refers to indexing multiple columns of a table.
Scenario 1:
A composite index (a, b) is sorted by a, b (first sorted by a, if a is the same then sorted by b). Therefore, the following statements can directly use the composite index to get results (in fact, it uses the leftmost prefix principle):
- select … from xxx where a=xxx;
- select … from xxx where a=xxx order by b;
The following statements cannot use composite queries:
- select … from xxx where b=xxx;
Scenario 2:
For a composite index (a, b, c), the following statements can directly get results through the composite index:
- select … from xxx where a=xxx order by b;
- select … from xxx where a=xxx and b=xxx order by c;
The following statements cannot use the composite index and require a filesort operation:
- select … from xxx where a=xxx order by c;
Summary:
Using the composite index (a, b, c) as an example, creating such an index is equivalent to creating indexes a, ab, and abc. Having one index replace three indexes is certainly beneficial, as each additional index increases the overhead of write operations and disk space usage.
4. Leftmost Prefix Principle
- From the above composite index example, we can understand the leftmost prefix principle.
- Not just the full definition of the index, as long as it meets the leftmost prefix, it can be used to speed up retrieval. This leftmost prefix can be the leftmost N fields of the composite index or the leftmost M characters of the string index. Use the "leftmost prefix" principle of the index to locate records and avoid redundant index definitions.
- Therefore, based on the leftmost prefix principle, it is crucial to consider the field order within the index when defining composite indexes! The evaluation criterion is the reusability of the index. For example, when there is already an index on (a, b), there is generally no need to create a separate index on a.
5. Index Pushdown
MySQL 5.6 introduced the index pushdown optimization, which can filter out records that do not meet the conditions based on the fields included in the index during index traversal, reducing the number of table lookups.
- Create table
CREATE TABLE `test` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'Auto-increment primary key', `age` int(11) NOT NULL DEFAULT '0', `name` varchar(255) CHARACTER SET utf8 NOT NULL DEFAULT '', PRIMARY KEY (`id`), KEY `idx_name_age` (`name`,`age`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
- SELECT * from user where name like 'Chen%' Leftmost prefix principle, hitting idx_name_age index
-
SELECT * from user where name like 'Chen%' and age=20
- Before version 5.6, it would first match 2 records based on the name index (ignoring the age=20 condition at this point), find the corresponding 2 IDs, perform table lookups, and then filter based on age=20.
- After version 5.6, index pushdown is introduced. After matching 2 records based on name, it will not ignore the age=20 condition before performing table lookups, filtering based on age before table lookup. This index pushdown can reduce the number of table lookups and improve query performance.
6. Prefix Index
When an index is a long character sequence, it can take up a lot of memory and be slow. In this case, prefix indexes can be used. Instead of indexing the entire value, we index the first few characters to save space and achieve good performance. Prefix index uses the first few letters of the index. However, to reduce the index duplication rate, we must evaluate the uniqueness of the prefix index.
- First, calculate the uniqueness ratio of the current string field: select 1.0*count(distinct name)/count(*) from test
- Then, calculate the uniqueness ratio for different prefixes:
- select 1.0*count(distinct left(name,1))/count(*) from test for the first character of the name as the prefix index
- select 1.0*count(distinct left(name,2))/count(*) from test for the first two characters of the name as the prefix index
- ...
- When left(str, n) does not significantly increase, select n as the prefix index cut-off value.
- Create the index alter table test add key(name(n));
4. [Viewing Indexes]
After adding indexes, how do we view them? Or, if statements are slow to execute, how do we troubleshoot?
Explain is commonly used to check if an index is effective.
After obtaining the slow query log, observe which statements are slow. Add explain before the statement and execute it again. Explain sets a flag on the query, causing it to return information about each step in the execution plan instead of executing the statement. It returns one or more rows of information showing each part of the execution plan and the execution order.
Important fields returned by explain:
- type: Shows the search method (full table scan or index scan)
- key: The index field used, null if not used
Explain's type field:
- ALL: Full table scan
- index: Full index scan
- range: Index range scan
- ref: Non-unique index scan
- eq_ref: Unique index scan
-
 Go语言如何动态发现导出包类型?与反射软件包中的有限类型的发现能力相反,本文探索了替代方法,探索了在Runruntime。go import( “ FMT” “去/进口商” ) func main(){ pkg,err:= incorter.default()。导入(“ time”) 如果err...编程 发布于2025-07-17
Go语言如何动态发现导出包类型?与反射软件包中的有限类型的发现能力相反,本文探索了替代方法,探索了在Runruntime。go import( “ FMT” “去/进口商” ) func main(){ pkg,err:= incorter.default()。导入(“ time”) 如果err...编程 发布于2025-07-17 -
哪种方法更有效地用于点 - 填点检测:射线跟踪或matplotlib \的路径contains_points?在Python Matplotlib's path.contains_points FunctionMatplotlib's path.contains_points function employs a path object to represent the polygon.它...编程 发布于2025-07-17
-
如何在其容器中为DIV创建平滑的左右CSS动画?通用CSS动画,用于左右运动 ,我们将探索创建一个通用的CSS动画,以向左和右移动DIV,从而到达其容器的边缘。该动画可以应用于具有绝对定位的任何div,无论其未知长度如何。问题:使用左直接导致瞬时消失 更加流畅的解决方案:混合转换和左 [并实现平稳的,线性的运动,我们介绍了线性的转换。这...编程 发布于2025-07-17
-
C++中如何将独占指针作为函数或构造函数参数传递?在构造函数和函数中将唯一的指数管理为参数 unique pointers( unique_ptr [2启示。通过值: base(std :: simelor_ptr n) :next(std :: move(n)){} 此方法将唯一指针的所有权转移到函数/对象。指针的内容被移至功能中,在操作...编程 发布于2025-07-17
-
eval()vs. ast.literal_eval():对于用户输入,哪个Python函数更安全?称量()和ast.literal_eval()中的Python Security 在使用用户输入时,必须优先确保安全性。强大的Python功能Eval()通常是作为潜在解决方案而出现的,但担心其潜在风险。 This article delves into the differences betwee...编程 发布于2025-07-17
-
如何在JavaScript对象中动态设置键?在尝试为JavaScript对象创建动态键时,如何使用此Syntax jsObj['key' i] = 'example' 1;不工作。正确的方法采用方括号: jsobj ['key''i] ='example'1; 在JavaScript中,数组是一...编程 发布于2025-07-17
-
PHP与C++函数重载处理的区别作为经验丰富的C开发人员脱离谜题,您可能会遇到功能超载的概念。这个概念虽然在C中普遍,但在PHP中构成了独特的挑战。让我们深入研究PHP功能过载的复杂性,并探索其提供的可能性。在PHP中理解php的方法在PHP中,函数超载的概念(如C等语言)不存在。函数签名仅由其名称定义,而与他们的参数列表无关。...编程 发布于2025-07-17
-
如何将PANDAS DataFrame列转换为DateTime格式并按日期过滤?Transform Pandas DataFrame Column to DateTime FormatScenario:Data within a Pandas DataFrame often exists in various formats, including strings.使用时间数据时...编程 发布于2025-07-17
-
如何在Java中正确显示“ DD/MM/YYYY HH:MM:SS.SS”格式的当前日期和时间?如何在“ dd/mm/yyyy hh:mm:mm:ss.ss”格式“ gormat 解决方案:的,请访问量很大,并应为procectiquiestate的,并在整个代码上正确格式不多: java.text.simpledateformat; 导入java.util.calendar; 导入java...编程 发布于2025-07-17
-
如何使用组在MySQL中旋转数据?在关系数据库中使用mySQL组使用mySQL组进行查询结果,在关系数据库中使用MySQL组,转移数据的数据是指重新排列的行和列的重排以增强数据可视化。在这里,我们面对一个共同的挑战:使用组的组将数据从基于行的基于列的转换为基于列。 Let's consider the following ...编程 发布于2025-07-17
-
Java字符串非空且非null的有效检查方法检查字符串是否不是null而不是空的if (str != null && !str.isEmpty())Option 2: str.length() == 0For Java versions prior to 1.6, str.length() == 0 can be二手: if(str!= n...编程 发布于2025-07-17
-
如何将MySQL数据库添加到Visual Studio 2012中的数据源对话框中?在Visual Studio 2012 尽管已安装了MySQL Connector v.6.5.4,但无法将MySQL数据库添加到实体框架的“ DataSource对话框”中。为了解决这一问题,至关重要的是要了解MySQL连接器v.6.5.5及以后的6.6.x版本将提供MySQL的官方Visual...编程 发布于2025-07-17
-
Java为何无法创建泛型数组?通用阵列创建错误 arrayList [2]; JAVA报告了“通用数组创建”错误。为什么不允许这样做?答案:Create an Auxiliary Class:public static ArrayList<myObject>[] a = new ArrayList<myO...编程 发布于2025-07-17
-
如何使用node-mysql在单个查询中执行多个SQL语句?Multi-Statement Query Support in Node-MySQLIn Node.js, the question arises when executing multiple SQL statements in a single query using the node-mys...编程 发布于2025-07-17
-
在PHP中如何高效检测空数组?在PHP 中检查一个空数组可以通过各种方法在PHP中确定一个空数组。如果需要验证任何数组元素的存在,则PHP的松散键入允许对数组本身进行直接评估:一种更严格的方法涉及使用count()函数: if(count(count($ playerList)=== 0){ //列表为空。 } 对...编程 发布于2025-07-17















学习中文
- 1 走路用中文怎么说?走路中文发音,走路中文学习
- 2 坐飞机用中文怎么说?坐飞机中文发音,坐飞机中文学习
- 3 坐火车用中文怎么说?坐火车中文发音,坐火车中文学习
- 4 坐车用中文怎么说?坐车中文发音,坐车中文学习
- 5 开车用中文怎么说?开车中文发音,开车中文学习
- 6 游泳用中文怎么说?游泳中文发音,游泳中文学习
- 7 骑自行车用中文怎么说?骑自行车中文发音,骑自行车中文学习
- 8 你好用中文怎么说?你好中文发音,你好中文学习
- 9 谢谢用中文怎么说?谢谢中文发音,谢谢中文学习
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









