
import streamlit as stimport numpy as npimport pandas as pdimport joblib
stremlit 是一个 Python 库,可以轻松地为机器学习和数据科学项目创建和共享自定义 Web 应用程序。
numpy 是用于数值计算的基本 Python 库。它提供对大型多维数组和矩阵的支持,以及一组数学函数来有效地对这些数组进行操作。
data = { \\\"island\\\": island, \\\"bill_length_mm\\\": bill_length_mm, \\\"bill_depth_mm\\\": bill_depth_mm, \\\"flipper_length_mm\\\": flipper_length_mm, \\\"body_mass_g\\\": body_mass_g, \\\"sex\\\": sex,}input_df = pd.DataFrame(data, index=[0])encode = [\\\"island\\\", \\\"sex\\\"]input_encoded_df = pd.get_dummies(input_df, prefix=encode)输入值是从 Stremlit 创建的输入表单中检索的,分类变量使用与创建模型时相同的规则进行编码。请注意,每个数据的顺序也必须与创建模型时的顺序相同。如果顺序不同,使用模型执行预测时将会出现错误。
clf = joblib.load(\\\"penguin_classifier_model.pkl\\\")
“penguin_classifier_model.pkl”是存储之前保存的模型的文件。该文件包含经过训练的二进制格式的 RandomForestClassifier。运行此代码会将模型加载到 clf 中,允许您使用它对新数据进行预测和评估。
prediction = clf.predict(input_encoded_df)prediction_proba = clf.predict_proba(input_encoded_df)
clf.predict(input_encoded_df):使用训练好的模型来预测新编码输入数据的类别,并将结果存储在预测中。
clf.predict_proba(input_encoded_df):计算每个类的概率,将结果存储在prediction_proba.
您可以通过访问 Stremlit 社区云 (https://streamlit.io/cloud) 并指定 GitHub 存储库的 URL 在 Internet 上发布您开发的应用程序。

@allison_horst 的作品 (https://github.com/allisonhorst)
该模型使用 Palmer Penguins 数据集进行训练,这是一个广泛认可的用于练习机器学习技术的数据集。该数据集提供了来自南极洲帕尔默群岛的三种企鹅(阿德利企鹅、帽带企鹅和巴布亚企鹅)的信息。主要功能包括:
该数据集源自 Kaggle,可以在此处访问。特征的多样性使其成为构建分类模型和了解每个特征在物种预测中的重要性的绝佳选择。
","image":"http://www.luping.net/uploads/20241006/17282217676702924713227.png","datePublished":"2024-11-02T21:56:21+08:00","dateModified":"2024-11-02T21:56:21+08:00","author":{"@type":"Person","name":"luping.net","url":"https://www.luping.net/articlelist/0_1.html"}} 浏览:452
浏览:452
机器学习模型本质上是一组用于进行预测或查找数据模式的规则或机制。简单地说(不用担心过于简单化),在 Excel 中使用最小二乘法计算的趋势线也是一个模型。然而,实际应用中使用的模型并不那么简单——它们通常涉及更复杂的方程和算法,而不仅仅是简单的方程。
在这篇文章中,我将首先构建一个非常简单的机器学习模型,并将其作为一个非常简单的 Web 应用程序发布,以了解该过程。
在这里,我将只关注流程,而不是 ML 模型本身。另外,我将使用 Streamlit 和 Streamlit Community Cloud 轻松发布 Python Web 应用程序。
使用 scikit-learn(一种流行的机器学习 Python 库),您可以快速训练数据并创建模型,只需几行代码即可完成简单任务。然后可以使用 joblib 将模型保存为可重用文件。这个保存的模型可以像 Web 应用程序中的常规 Python 库一样导入/加载,从而允许应用程序使用经过训练的模型进行预测!
应用程序网址:https://yh-machine-learning.streamlit.app/
GitHub:https://github.com/yoshan0921/yh-machine-learning.git
此应用程序允许您检查在帕尔默企鹅数据集上训练的随机森林模型所做的预测。 (有关训练数据的更多详细信息,请参阅本文末尾。)
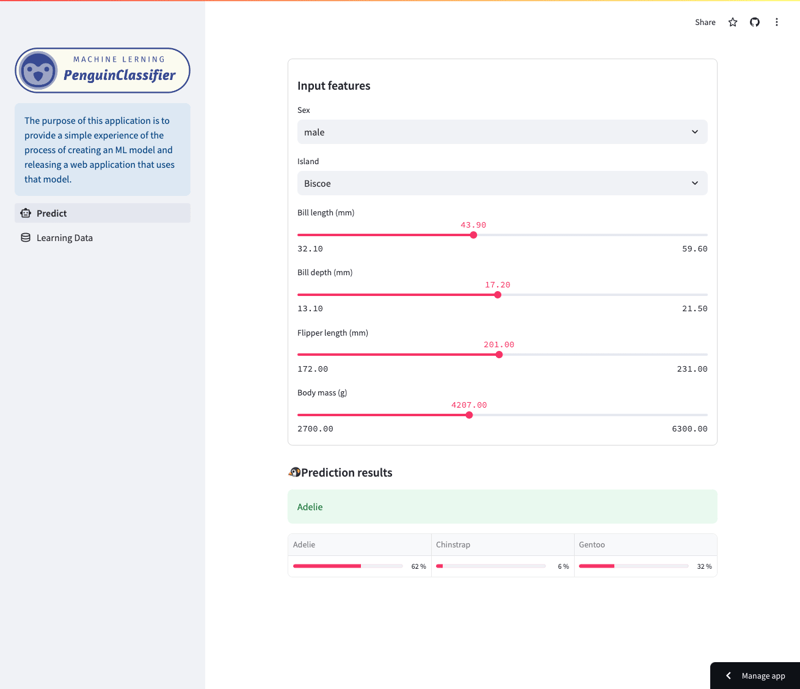
具体来说,该模型根据各种特征预测企鹅物种,包括物种、岛屿、喙长、鳍状肢长度、体型和性别。用户可以导航应用程序以查看不同的功能如何影响模型的预测。
预测屏幕
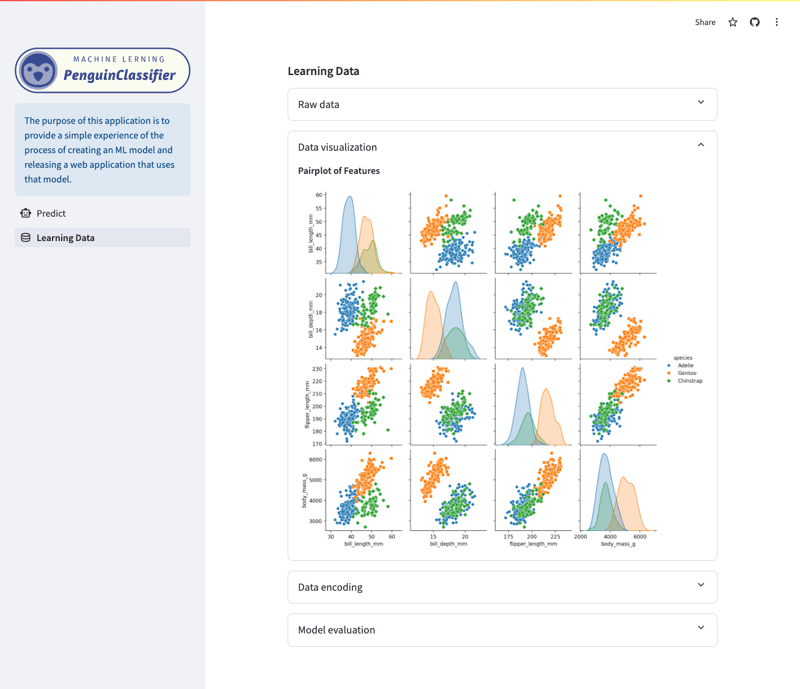
学习数据/可视化屏幕
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score import joblib
pandas是一个专门用于数据操作和分析的Python库。它支持使用 DataFrame 进行数据加载、预处理和结构化,为机器学习模型准备数据。
sklearn 是一个用于机器学习的综合 Python 库,提供训练和评估工具。在这篇文章中,我将使用称为随机森林的学习方法构建一个模型。
joblib 是一个 Python 库,可帮助以非常有效的方式保存和加载 Python 对象,例如机器学习模型。
df = pd.read_csv("./dataset/penguins_cleaned.csv")
X_raw = df.drop("species", axis=1)
y_raw = df.species
加载数据集(训练数据)并将其分成特征(X)和目标变量(y)。
encode = ["island", "sex"]
X_encoded = pd.get_dummies(X_raw, columns=encode)
target_mapper = {"Adelie": 0, "Chinstrap": 1, "Gentoo": 2}
y_encoded = y_raw.apply(lambda x: target_mapper[x])
使用 one-hot 编码(X_encoded)将分类变量转换为数字格式。例如,如果“island”包含类别“Biscoe”、“Dream”和“Torgersen”,则会为每个类别创建一个新列(island_Biscoe、island_Dream、island_Torgersen)。对于性也是如此。如果原始数据是“Biscoe”,则 island_Biscoe 列将设置为 1,其他列将设置为 0。
目标变量物种映射到数值(y_encoded)。
x_train, x_test, y_train, y_test = train_test_split(
X_encoded, y_encoded, test_size=0.3, random_state=1
)
为了评估模型,有必要衡量模型在未用于训练的数据上的性能。 7:3 被广泛用作机器学习中的一般实践。
clf = RandomForestClassifier() clf.fit(x_train, y_train)
拟合方法用于训练模型。
x_train 表示解释变量的训练数据,y_train 表示目标变量。
通过调用该方法,根据训练数据训练出来的模型存储在clf.
joblib.dump(clf, "penguin_classifier_model.pkl")
joblib.dump()是以二进制格式保存Python对象的函数。通过以此格式保存模型,可以从文件加载模型并按原样使用,而无需再次训练。
import streamlit as st import numpy as np import pandas as pd import joblib
stremlit 是一个 Python 库,可以轻松地为机器学习和数据科学项目创建和共享自定义 Web 应用程序。
numpy 是用于数值计算的基本 Python 库。它提供对大型多维数组和矩阵的支持,以及一组数学函数来有效地对这些数组进行操作。
data = {
"island": island,
"bill_length_mm": bill_length_mm,
"bill_depth_mm": bill_depth_mm,
"flipper_length_mm": flipper_length_mm,
"body_mass_g": body_mass_g,
"sex": sex,
}
input_df = pd.DataFrame(data, index=[0])
encode = ["island", "sex"]
input_encoded_df = pd.get_dummies(input_df, prefix=encode)
输入值是从 Stremlit 创建的输入表单中检索的,分类变量使用与创建模型时相同的规则进行编码。请注意,每个数据的顺序也必须与创建模型时的顺序相同。如果顺序不同,使用模型执行预测时将会出现错误。
clf = joblib.load("penguin_classifier_model.pkl")
“penguin_classifier_model.pkl”是存储之前保存的模型的文件。该文件包含经过训练的二进制格式的 RandomForestClassifier。运行此代码会将模型加载到 clf 中,允许您使用它对新数据进行预测和评估。
prediction = clf.predict(input_encoded_df) prediction_proba = clf.predict_proba(input_encoded_df)
clf.predict(input_encoded_df):使用训练好的模型来预测新编码输入数据的类别,并将结果存储在预测中。
clf.predict_proba(input_encoded_df):计算每个类的概率,将结果存储在prediction_proba.
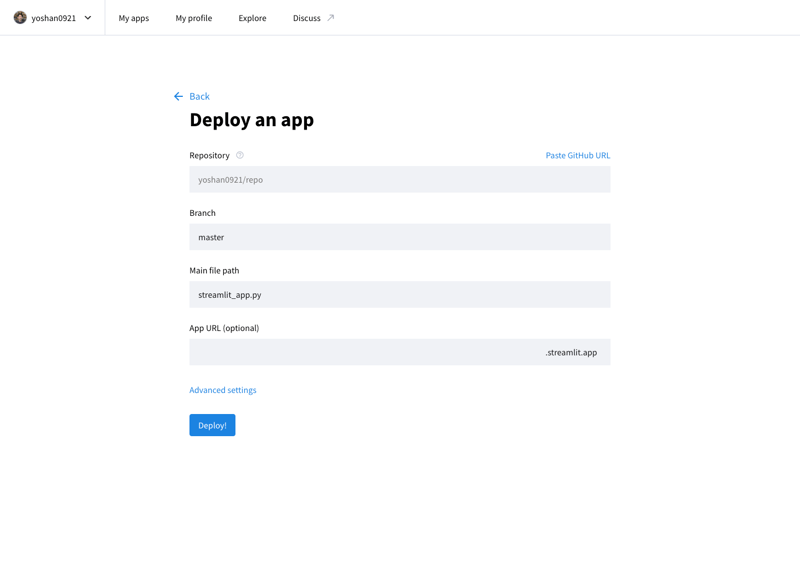
您可以通过访问 Stremlit 社区云 (https://streamlit.io/cloud) 并指定 GitHub 存储库的 URL 在 Internet 上发布您开发的应用程序。

@allison_horst 的作品 (https://github.com/allisonhorst)
该模型使用 Palmer Penguins 数据集进行训练,这是一个广泛认可的用于练习机器学习技术的数据集。该数据集提供了来自南极洲帕尔默群岛的三种企鹅(阿德利企鹅、帽带企鹅和巴布亚企鹅)的信息。主要功能包括:
该数据集源自 Kaggle,可以在此处访问。特征的多样性使其成为构建分类模型和了解每个特征在物种预测中的重要性的绝佳选择。















免责声明: 提供的所有资源部分来自互联网,如果有侵犯您的版权或其他权益,请说明详细缘由并提供版权或权益证明然后发到邮箱:[email protected] 我们会第一时间内为您处理。
Copyright© 2022 湘ICP备2022001581号-3










