 Primeira página > Programação > API de dados para Amazon Aurora Serverless com AWS SDK para Java - Parte Aurora Serverless vata API atende ao DevOps Guru ou não?
Primeira página > Programação > API de dados para Amazon Aurora Serverless com AWS SDK para Java - Parte Aurora Serverless vata API atende ao DevOps Guru ou não?
API de dados para Amazon Aurora Serverless com AWS SDK para Java - Parte Aurora Serverless vata API atende ao DevOps Guru ou não?
 Navegar:333
Navegar:333
Introdução
Em meu artigo Amazon DevOps Guru para aplicativos Serverless - Parte 10 Detecção de anomalias no Aurora Serverless v2, aprendemos que o DevOps Guru foi capaz de detectar anomalias com êxito com o banco de dados Aurora (Serverless v2) PostgreSQL no caso de função Lambda com Java 21 gerenciado o tempo de execução foi conectado a ele via JDBC. Escalamos nosso banco de dados apenas de 0,5 para 1 ACU e criamos uma carga muito alta no banco de dados invocando a função Lambda para recuperar o produto por ID várias centenas de vezes simultaneamente por vários minutos. Vimos que o DevOps Guru apontou corretamente para o aumento da soma de conexões de banco de dados e para a carga constantemente alta do banco de dados (CPU). Neste artigo, gostaria de descobrir se o DevOps Guru detectará a anomalia fazendo o mesmo experimento, mas usando a API de dados para Aurora Serverless v2 com AWS SDK para Java em vez de JDBC.
Detecção de anomalias no Aurora Serverless v2 com API de dados
Vamos dar uma olhada em nosso aplicativo de exemplo e usar o modelo SAM para criar infraestrutura e implantar o aplicativo descrito na imagem a seguir:
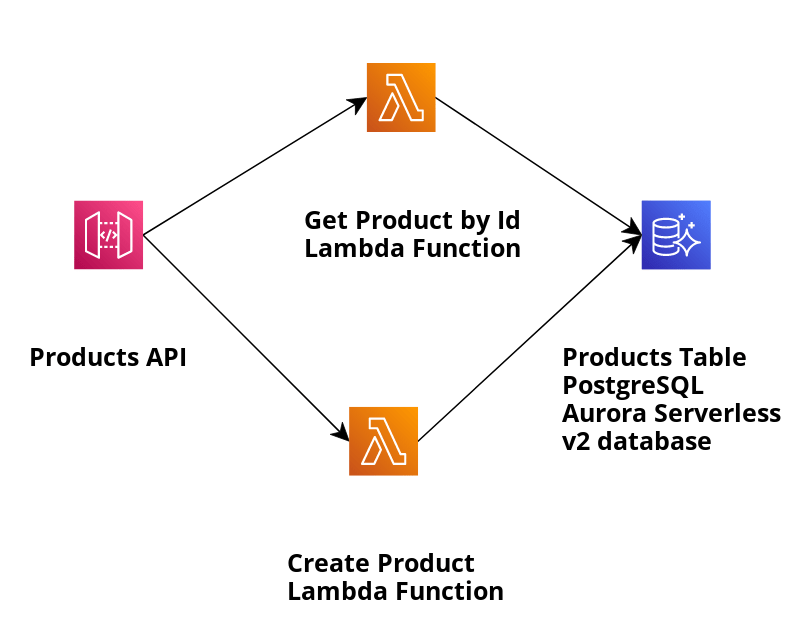
O aplicativo cria produtos armazenados no banco de dados Aurora Serverless v2 PostgreSQL e os recupera por ID usando a API de dados. A função Lambda relevante que usaremos para recuperar o produto por seu ID é GetProductByIdViaAuroraServerlessV2DataApi e sua implementação de manipulador é GetProductByIdViaAuroraServerlessV2DataApiHandler.
Como no artigo anterior, usamos a ferramenta hey para realizar o teste de estresse como este
hey -z 15m -c 300 -H "X-API-Key: XXXa6XXXX" https://XXX.execute-api.eu-central-1.amazonaws.com/prod/productsWithDataApi/1
Neste exemplo, invocamos o endpoint do API Gateway com 300 contêineres simultâneos por 15 minutos. Por trás do endpoint prod/productsWithoutDataApi, a função Lambda GetProductByIdViaAuroraServerlessV2WithoutDataApi será invocada, recuperando o produto pelo id 1 do banco de dados Aurora Serverless v2 PostgreSQL.
Configuramos em nosso [modelo SAM]((https://github.com/Vadym79/AWSLambdaJavaAuroraServerlessV2DataApi/blob/master/template.yaml) cluster de banco de dados Aurora para escalar da capacidade mínima de 0,5 para a capacidade máxima de 1 ACU (que é tamanho de banco de dados muito pequeno) no caso de aumento de carga para fins de redução de custos.
AuroraServerlessV2Cluster:
Type: 'AWS::RDS::DBCluster'
...
ServerlessV2ScalingConfiguration:
MinCapacity: 0.5
MaxCapacity: 1
O banco de dados Aurora (Serverless v2) gerencia o número máximo de conexões de banco de dados disponíveis proporcionalmente ao tamanho do banco de dados (em nosso caso, a configuração ACU) também com Data API para Aurora Serverless v2 (que é uma grande diferença para v1, que se tornará sem suporte no final do ano de 2024, onde havia uma cota rígida de 1.000 conexões de banco de dados por segundo). Para obter mais informações, leia a documentação sobre Conexões máximas para Aurora Serverless v2. Portanto, com o aumento do número de invocações, esperamos atingir em breve o número máximo de conexões de banco de dados disponíveis e alta carga de banco de dados (CPU), para que o banco de dados não seja capaz de responder às novas solicitações de função do Lambda para recuperar o produto por id (o Lambda também será executado). Com isso iremos provocar a anomalia e gostaríamos de saber se o DevOps Guru será capaz de detectá-la. E foi capaz, mais ou menos... O seguinte insight foi gerado:
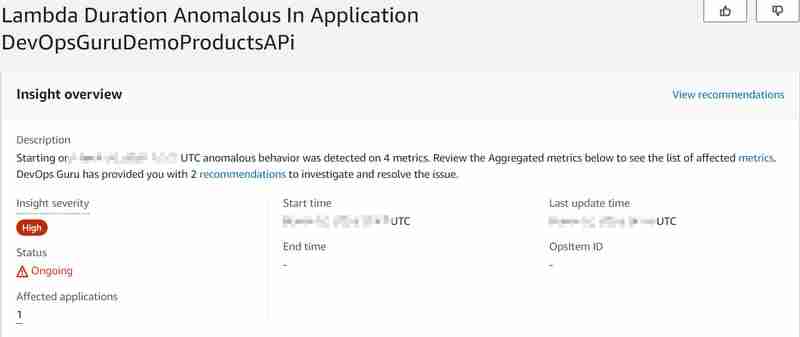
.
Em termos de utilização/escala da ACU, ambos parecem iguais:
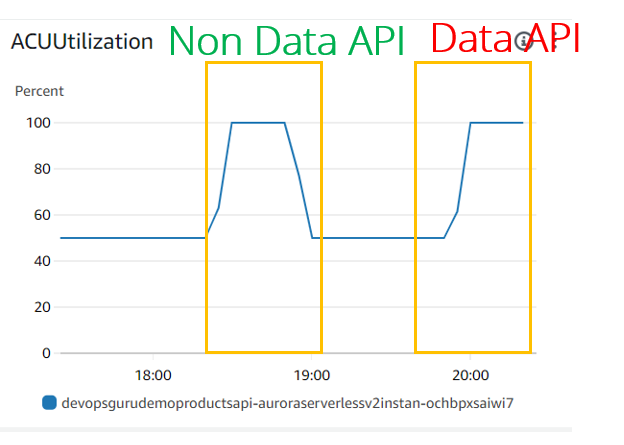
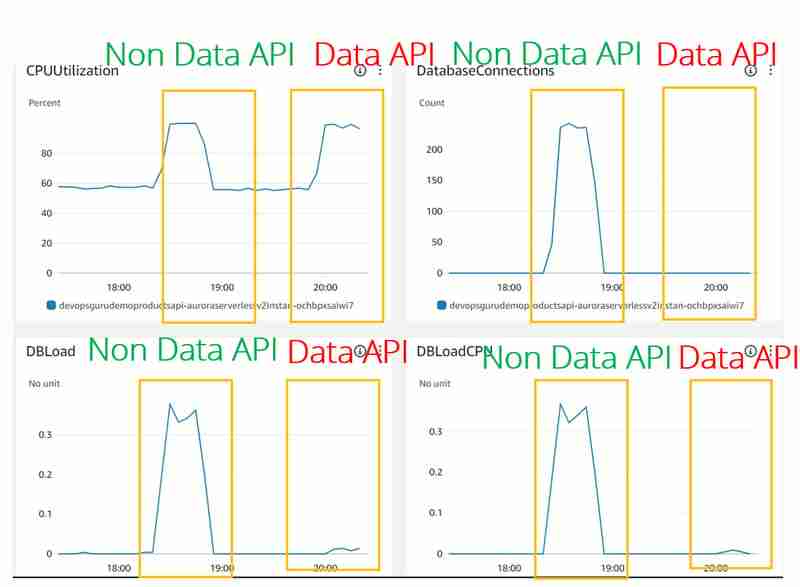
- A utilização da CPU parece a mesma para casos de JDBC (API não de dados) e API de dados. Mas o DevOps Guru parece não considerar essa métrica, pois não a vimos nem mesmo para o experimento JDBC
- DBLoad(CPU) que é muito baixo para uso da API de dados. Parece que para a API Dat existe algum Load Balancer na frente do banco de dados Aurora Serverless v2 que monitora o uso da conexão e protege o banco de dados contra sobrecarga.
- A métrica DatabaseConnection não é mostrada (ou mostrada como 0) para uso da API de dados. A razão para isso é que não gerenciamos a conexão do banco de dados para a API de dados, isso é feito do outro lado para nós. É claro que eles ainda desempenham um papel importante que aprendemos em Conexões máximas para Aurora Serverless v2, mas essa métrica parece estar exposta externamente nas métricas do CloudWatch e mesmo o DevOps Guru não tem acesso aos números reais.
- Com isso e DBLoad(CPU) muito baixo, nenhum insight do DevOps Guru para o cluster Aurora Serverless v2 com uso de API de dados foi gerado em comparação com o caso de uso JDBC.
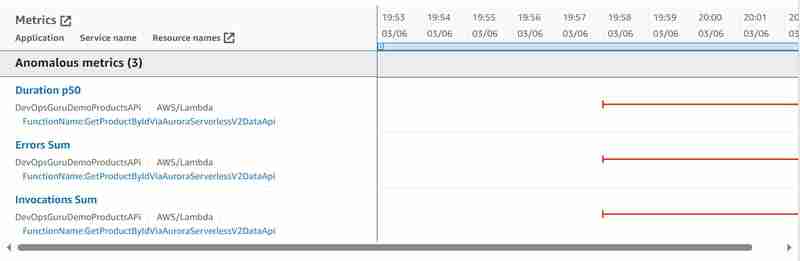
Fiz o segundo experimento conectando-me diretamente ao cluster Aurora Serverless v2 e escrevi o script para criar o teste de carga escrevendo o script que busca o produto por ID várias centenas de vezes usando a maneira padrão (API sem dados). Semelhante ao que fizemos com a ferramenta hey, mas acessando o banco de dados diretamente em vez de invocar o Api Gateway. Depois de colocar o banco de dados sob carga, iniciei o mesmo experimento com a ferramenta hey conforme descrito acima e queria ver o que aconteceria. O mesmo insight foi gerado, mas desta vez com as seguintes métricas anômalas:
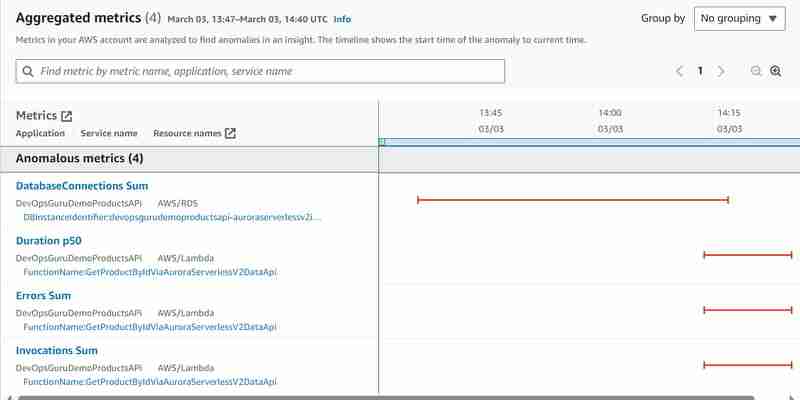 Agora vemos pelo menos uma métrica anômala de soma de conexão de banco de dados Aurora Serverless v2 adicional, mas as métricas DBLoad (CPU) ainda estão faltando.
Agora vemos pelo menos uma métrica anômala de soma de conexão de banco de dados Aurora Serverless v2 adicional, mas as métricas DBLoad (CPU) ainda estão faltando.
As anomalias gráficas têm esta aparência:
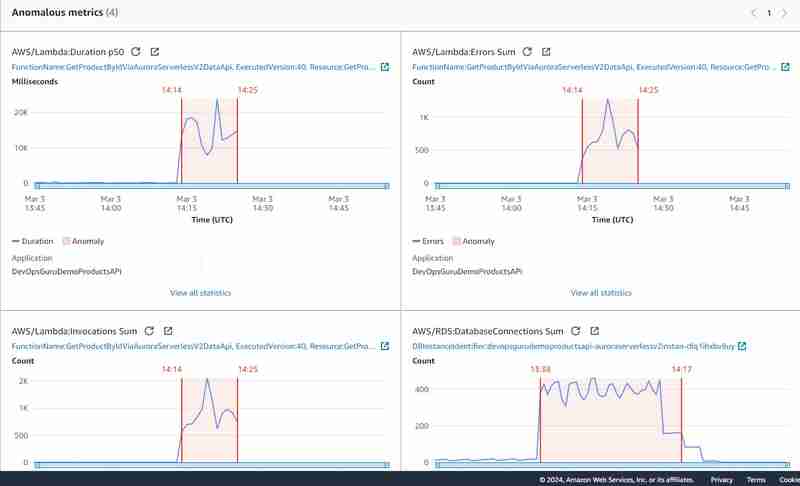 É claro que o experimento não foi limpo, pois fiz 2 testes de carga um após o outro e parcialmente em paralelo: o primeiro conectando-se ao banco de dados diretamente sem uso do API Gateway e o segundo usando Data API. Isso confirmou minha suposição inicial de que as métricas de soma de conexão do banco de dados são um critério muito importante para gerar insights do DevOps Guru para Aurora Serverless v2 (e para RDS em geral) e não são expostas em geral no caso de uso da API de dados.
É claro que o experimento não foi limpo, pois fiz 2 testes de carga um após o outro e parcialmente em paralelo: o primeiro conectando-se ao banco de dados diretamente sem uso do API Gateway e o segundo usando Data API. Isso confirmou minha suposição inicial de que as métricas de soma de conexão do banco de dados são um critério muito importante para gerar insights do DevOps Guru para Aurora Serverless v2 (e para RDS em geral) e não são expostas em geral no caso de uso da API de dados.
Conclusão
Neste artigo aprendi que o DevOps Guru pode detectar anomalias com sucesso com o banco de dados PostgreSQL Aurora (Serverless v2) no caso da função Lambda com tempo de execução gerenciado Java 21 conectado a ele via API de dados, mas só pode mostrar as métricas anômalas relacionadas à função Lambda sendo excedido porque o banco de dados não respondeu. A principal razão para isso parece ser que a conexão com o banco de dados como uma métrica do CloudWatch não é exposta (ou sempre exibida como 0) no caso de uso do Aurora Serverless v2 com API de dados. As métricas do banco de dados Aurora Serverless v2 (soma de conexões do banco de dados) só foram mostradas durante o segundo experimento artificial.
-
 Por que a execução do JavaScript cessa ao usar o botão Back Firefox?Problema do histórico de navegação: JavaScript deixa de executar após o uso do botão de volta ao Firefox usuários do Firefox podem encontrar u...Programação Postado em 2025-07-15
Por que a execução do JavaScript cessa ao usar o botão Back Firefox?Problema do histórico de navegação: JavaScript deixa de executar após o uso do botão de volta ao Firefox usuários do Firefox podem encontrar u...Programação Postado em 2025-07-15 -
O Java permite vários tipos de retorno: uma olhada mais próxima dos métodos genéricos?Tipos de retorno múltiplos em java: um equívoco revelado no reino da programação java, e um método peculiar pode surgir, deixando os desenvolv...Programação Postado em 2025-07-15
-
Razões para o Codeigniter se conectar ao banco de dados MySQL depois de mudar para MySqliUnable to Connect to MySQL Database: Troubleshooting Error MessageWhen attempting to switch from the MySQL driver to the MySQLi driver in CodeIgniter,...Programação Postado em 2025-07-15
-
Como o mapa de Java. ENTRY e Simpleentry simplificam o gerenciamento de pares de valores-chave?Uma coleção abrangente para pares de valores: introduzindo o mapa de java.Entry e o Simpleentry em java, ao definir uma coleção em que cada el...Programação Postado em 2025-07-15
-
Como corrigir “Erro geral: o servidor MySQL 2006 desapareceu” ao inserir dados?Como resolver "Erro geral: o servidor MySQL de 2006 desapareceu" ao inserir registrosIntrodução:A inserção de dados em um banco de dados MyS...Programação Postado em 2025-07-15
-
Preciso excluir explicitamente as alocações de heap em C ++ antes da saída do programa?exclusão explícita em c, apesar do programa exit ao trabalhar com a alocação de memória dinâmica em C, os desenvolvedores geralmente se pergun...Programação Postado em 2025-07-15
-
Como posso personalizar otimizações de compilação no compilador Go?personalizando otimizações de compilação no Go Compiler O processo de compilação padrão em Go segue uma estratégia de otimização específica. N...Programação Postado em 2025-07-15
-
Como resolver o erro "Não é possível adivinhar o tipo de arquivo, usar aplicativo/stream de octeto ..." no AppEngine?AppEngine Arquivo estático MIME TIPO SUBSENTIDE No AppEngine, os manipuladores de arquivos estáticos podem ocasionalmente substituir o tipo de...Programação Postado em 2025-07-15
-
Como você pode usar o Grupo By to Pivot Data in MySQL?girando resultados de consulta usando o grupo mysql por em um banco de dados relacional, girando dados se referindo ao rearranjo de linhas e c...Programação Postado em 2025-07-15
-
Como posso concatenar com segurança o texto e os valores ao construir consultas SQL em Go?concatenando texto e valores em go sql Queries Ao construir uma consulta SQL texth e, em codificação, e a signa e a consulta de syntax e a sín...Programação Postado em 2025-07-15
-
Os parâmetros de modelo podem na função C ++ 20 ConstEval depender dos parâmetros da função?funções constEval e parâmetros de modelos dependentes de argumentos de função em C 17, um parâmetro de modelo não pode depender de um argument...Programação Postado em 2025-07-15
-
Como analisar números na notação exponencial usando decimal.parse ()?analisando um número da notação exponencial ao tentar analisar uma string expressa em anotação exponencial usando Decimal.parse ("1.2345e...Programação Postado em 2025-07-15
-
Php simplexml analisando o método xml com namespace colonanalisando xml com namespace cenos em php simpxml encontra dificuldades ao analisar xml contendo tags com cônjuges, como xml elementos com pre...Programação Postado em 2025-07-15
-
Vários elementos pegajosos podem ser empilhados um no outro em CSS puro?É possível ter vários elementos pegajosos empilhados um no outro em CSS puro? O comportamento desejado pode ser visto Aqui: https://webtheme...Programação Postado em 2025-07-15
-
Como superar as restrições de redefinição da função do PHP?superando a função do PHP Redefinição limitações em php, definir uma função com o mesmo nome várias vezes é um não-no. Tentar fazê -lo, como v...Programação Postado em 2025-07-15















Estude chinês
- 1 Como se diz “andar” em chinês? 走路 Pronúncia chinesa, 走路 aprendizagem chinesa
- 2 Como se diz “pegar um avião” em chinês? 坐飞机 Pronúncia chinesa, 坐飞机 aprendizagem chinesa
- 3 Como se diz “pegar um trem” em chinês? 坐火车 Pronúncia chinesa, 坐火车 aprendizagem chinesa
- 4 Como se diz “pegar um ônibus” em chinês? 坐车 Pronúncia chinesa, 坐车 aprendizagem chinesa
- 5 Como se diz dirigir em chinês? 开车 Pronúncia chinesa, 开车 aprendizagem chinesa
- 6 Como se diz nadar em chinês? 游泳 Pronúncia chinesa, 游泳 aprendizagem chinesa
- 7 Como se diz andar de bicicleta em chinês? 骑自行车 Pronúncia chinesa, 骑自行车 aprendizagem chinesa
- 8 Como você diz olá em chinês? 你好Pronúncia chinesa, 你好Aprendizagem chinesa
- 9 Como você agradece em chinês? 谢谢Pronúncia chinesa, 谢谢Aprendizagem chinesa
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









