
Converta uma string em camelCase usando esta função em Javascript.
 Navegar:288
Navegar:288
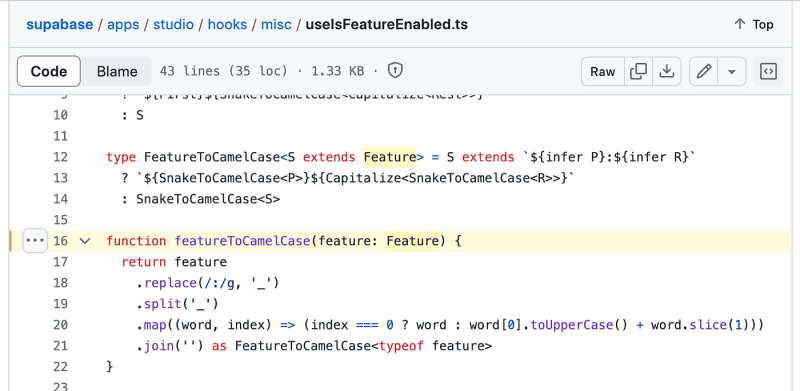
Já precisou converter uma string para camelCase? Encontrei um trecho de código interessante enquanto explorava o repositório Supabase de código aberto. Este é o método que eles usam:
function featureToCamelCase(feature: Feature) {
return feature
.replace(/:/g, '\_')
.split('\_')
.map((word, index) => (index === 0 ? word : word\[0\].toUpperCase() word.slice(1)))
.join('') as FeatureToCamelCase
}
Esta função é muito legal. Ele substitui dois pontos por sublinhados, divide a string em palavras e, em seguida, mapeia cada palavra para convertê-la em camelCase. A primeira palavra é mantida em letras minúsculas e as palavras subsequentes têm seu primeiro caractere em maiúscula antes de serem unidas novamente. Simples, mas eficaz!
Me deparei com outra abordagem no Stack Overflow que não usa expressões regulares. Aqui está a alternativa:
function toCamelCase(str) {
return str.split(' ').map(function(word, index) {
// If it is the first word make sure to lowercase all the chars.
if (index == 0) {
return word.toLowerCase();
}
// If it is not the first word only upper case the first char and lowercase the rest.
return word.charAt(0).toUpperCase() word.slice(1).toLowerCase();
}).join('');
}
Este trecho de código do SO contém comentários explicando o que esse código faz, exceto que não usa nenhum tipo de regex. O código encontrado na forma de conversão de uma string para camelCase do Supabase é muito semelhante a esta resposta do SO, exceto pelos comentários e pelo regex usado.
.replace(/:/g, '\_')
Este método divide a string por espaços e depois mapeia cada palavra. A primeira palavra está inteiramente em letras minúsculas, enquanto as palavras subsequentes são maiúsculas no primeiro caractere e minúsculas no restante. Finalmente, as palavras são unidas novamente para formar uma string camelCase.
Um comentário interessante de um usuário do Stack Overflow mencionou a vantagem de desempenho desta abordagem:
“ 1 por não usar expressões regulares, mesmo que a pergunta pedisse uma solução usando-as. Esta é uma solução muito mais clara e também uma clara vitória para o desempenho (porque processar expressões regulares complexas é uma tarefa muito mais difícil do que apenas iterar um monte de strings e juntar pedaços delas). Veja jsperf.com/camel-casing-regexp-or-character-manipulation/1 onde peguei alguns dos exemplos aqui junto com este (e também meu próprio modesto melhoria para desempenho, embora eu provavelmente prefira esta versão por uma questão de clareza na maioria dos casos).”
Ambos os métodos têm seus méritos. A abordagem regex no código Supabase é concisa e aproveita técnicas poderosas de manipulação de strings. Por outro lado, a abordagem não-regex é elogiada pela sua clareza e desempenho, pois evita a sobrecarga computacional associada às expressões regulares.
Veja como você pode escolher entre eles:
- Use a abordagem regex se precisar de uma solução compacta e de uma linha que aproveite os poderosos recursos de regex do JavaScript. Certifique-se também de adicionar comentários explicando o que seu regex faz, para que seu futuro ou próximo desenvolvedor trabalhando com seu código possa entender.
- Opte pelo método não regex se você prioriza legibilidade e desempenho, especialmente ao lidar com strings mais longas ou executar essa conversão várias vezes.
Quer aprender como construir shadcn-ui/ui do zero? Confira construir do zero
Sobre mim:
Site: https://ramunarasinga.com/
Linkedin: https://www.linkedin.com/in/ramu-narasinga-189361128/
Github: https://github.com/Ramu-Narasinga
E-mail: [email protected]
Construa shadcn-ui/ui do zero
Referências:
- https://github.com/supabase/supabase/blob/master/apps/studio/hooks/misc/useIsFeatureEnabled.ts#L16
- https://stackoverflow.com/a/35976812
-
 Como posso iterar de maneira síncrona e imprimir valores de duas matrizes de tamanho igual no PHP?iterando e imprimindo valores de duas matrizes do mesmo tamanho ao criar uma caixa selecionada usando duas matrizes de tamanho igual, um contend...Programação Postado em 2025-05-18
Como posso iterar de maneira síncrona e imprimir valores de duas matrizes de tamanho igual no PHP?iterando e imprimindo valores de duas matrizes do mesmo tamanho ao criar uma caixa selecionada usando duas matrizes de tamanho igual, um contend...Programação Postado em 2025-05-18 -
Como ignorar os blocos de sites com os pedidos da Python e os agentes de usuários falsos?como simular o comportamento do navegador com as solicitações de Python e os agentes de usuário falsos Python's Solicts Library é uma ferr...Programação Postado em 2025-05-18
-
Como redirecionar vários tipos de usuários (alunos, professores e administradores) para suas respectivas atividades em um aplicativo Firebase?RED: Como redirecionar vários tipos de usuário para as respectivas atividades compreender o problema e um aplicativo de votamento de que é...Programação Postado em 2025-05-18
-
Como analisar as matrizes json em Go usando o pacote `json`?analisando as matrizes json em go com o pacote json Problem: como você pode analisar uma string json representando um array em Go usando o p...Programação Postado em 2025-05-18
-
Como resolver \ "Recusou -se a carregar erros de script ..." devido à política de segurança de conteúdo do Android?revelando o mistério: Erros de diretiva de política de segurança do conteúdo encontrando o erro enigmático "recusou -se a carregar o scri...Programação Postado em 2025-05-18
-
Como obter a fonte renderizada real em JavaScript quando o atributo de fonte CSS é indefinido?Acessando a fonte renderizada real quando indefinido em CSS ao acessar as propriedades da font de um elemento, o SettyStSELTSLEIRT RELLURT REL...Programação Postado em 2025-05-18
-
Php simplexml analisando o método xml com namespace colonanalisando xml com namespace cenos em php simpxml encontra dificuldades ao analisar xml contendo tags com cônjuges, como xml elementos com pre...Programação Postado em 2025-05-18
-
Por que não está aparecendo na minha imagem de fundo do CSS?SOLHAÇÃO DE TRABALHO: CSS Imagem de fundo não apareceu Você encontrou um problema em que sua imagem em segundo plano falha, apesar das seguint...Programação Postado em 2025-05-18
-
Resolva a exceção \\ "String Value \\" quando o MySQL insere emojiResolvando a exceção do valor da string incorreta ao inserir emoji ao tentar inserir uma string contendo caracteres emoji em um banco de dados M...Programação Postado em 2025-05-18
-
Como mesclar colunas de ano e quarto em uma coluna periódica em pandas?colunas concatenas para uma nova coluna de período Declaração de problemas: considera um panda dataframe com colunas denominadas "ano...Programação Postado em 2025-05-18
-
Como o mapa de Java. ENTRY e Simpleentry simplificam o gerenciamento de pares de valores-chave?Uma coleção abrangente para pares de valores: introduzindo o mapa de java.Entry e o Simpleentry em java, ao definir uma coleção em que cada el...Programação Postado em 2025-05-18
-
Como evitar vazamentos de memória ao fatiar a linguagem?vazamento de memória em go slies Compreendendo os vazamentos de memória nas fatias Go pode ser um desafio. Este artigo tem como objetivo forne...Programação Postado em 2025-05-18
-
Usuário Formato de tempo local e Guia de exibição de deslocamento de fuso horárioexibindo data/hora no formato de localidade do usuário com o time offset abordagem: A abordagem recomendada é lidar com a formatação de dat...Programação Postado em 2025-05-18
-
Como os desenvolvedores de Java protegem as credenciais do banco de dados da decompilação?protegendo as credenciais do banco de dados da decompilação em java em java, os arquivos de classe de decomposição são relativamente simples. ...Programação Postado em 2025-05-18
-
Como localizar a imagem de fundo CSS da direita?posicionar a imagem de fundo da direita com css no reino do desenvolvimento da web, geralmente é desejável posicionar com precisão imagens de ...Programação Postado em 2025-05-18















Estude chinês
- 1 Como se diz “andar” em chinês? 走路 Pronúncia chinesa, 走路 aprendizagem chinesa
- 2 Como se diz “pegar um avião” em chinês? 坐飞机 Pronúncia chinesa, 坐飞机 aprendizagem chinesa
- 3 Como se diz “pegar um trem” em chinês? 坐火车 Pronúncia chinesa, 坐火车 aprendizagem chinesa
- 4 Como se diz “pegar um ônibus” em chinês? 坐车 Pronúncia chinesa, 坐车 aprendizagem chinesa
- 5 Como se diz dirigir em chinês? 开车 Pronúncia chinesa, 开车 aprendizagem chinesa
- 6 Como se diz nadar em chinês? 游泳 Pronúncia chinesa, 游泳 aprendizagem chinesa
- 7 Como se diz andar de bicicleta em chinês? 骑自行车 Pronúncia chinesa, 骑自行车 aprendizagem chinesa
- 8 Como você diz olá em chinês? 你好Pronúncia chinesa, 你好Aprendizagem chinesa
- 9 Como você agradece em chinês? 谢谢Pronúncia chinesa, 谢谢Aprendizagem chinesa
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









