 Primeira página > Programação > Construindo um sistema de pesquisa semântica rápido e eficiente usando OpenVINO e Postgres
Primeira página > Programação > Construindo um sistema de pesquisa semântica rápido e eficiente usando OpenVINO e Postgres
Construindo um sistema de pesquisa semântica rápido e eficiente usando OpenVINO e Postgres
 Navegar:850
Navegar:850

Foto de real-napster no Pixabay
Em um de meus projetos recentes, tive que construir um sistema de pesquisa semântica que pudesse ser dimensionado com alto desempenho e fornecer respostas em tempo real para pesquisas de relatórios. Usamos PostgreSQL com pgvector no AWS RDS, emparelhado com AWS Lambda, para conseguir isso. O desafio era permitir que os usuários pesquisassem usando consultas em linguagem natural em vez de depender de palavras-chave rígidas, garantindo ao mesmo tempo que as respostas demorassem menos de 1 a 2 segundos ou até menos e só pudessem aproveitar os recursos da CPU.
Neste post, abordarei as etapas que executei para construir esse sistema de pesquisa, desde a recuperação até a reclassificação, e as otimizações feitas usando OpenVINO e lote inteligente para tokenização.
Visão geral da pesquisa semântica: recuperação e reclassificação
Os sistemas de pesquisa modernos e de última geração geralmente consistem em duas etapas principais: recuperação e reclassificação.
1) Recuperação: A primeira etapa envolve a recuperação de um subconjunto de documentos relevantes com base na consulta do usuário. Isso pode ser feito usando modelos de embeddings pré-treinados, como embeddings pequenos e grandes da OpenAI, modelos Embed de Cohere ou embeddings mxbai de Mixbread. A recuperação se concentra em restringir o conjunto de documentos medindo sua semelhança com a consulta.
Aqui está um exemplo simplificado usando a biblioteca de transformadores de frases do Huggingface para recuperação, que é uma das minhas bibliotecas favoritas para isso:
from sentence_transformers import SentenceTransformer
import numpy as np
# Load a pre-trained sentence transformer model
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
# Sample query and documents (vectorize the query and the documents)
query = "How do I fix a broken landing gear?"
documents = ["Report 1 on landing gear failure", "Report 2 on engine problems"]
# Get embeddings for query and documents
query_embedding = model.encode(query)
document_embeddings = model.encode(documents)
# Calculate cosine similarity between query and documents
similarities = np.dot(document_embeddings, query_embedding)
# Retrieve top-k most relevant documents
top_k = np.argsort(similarities)[-5:]
print("Top 5 documents:", [documents[i] for i in top_k])
2) Reclassificação: Uma vez recuperados os documentos mais relevantes, melhoramos ainda mais a classificação desses documentos usando um modelo cross-encoder. Esta etapa reavalia cada documento em relação à consulta com mais precisão, focando em uma compreensão contextual mais profunda.
A reclassificação é benéfica porque adiciona uma camada adicional de refinamento ao pontuar a relevância de cada documento com mais precisão.
Aqui está um exemplo de código para reclassificação usando cross-encoder/ms-marco-TinyBERT-L-2-v2, um cross-encoder leve:
from sentence_transformers import CrossEncoder
# Load the cross-encoder model
cross_encoder = CrossEncoder("cross-encoder/ms-marco-TinyBERT-L-2-v2")
# Use the cross-encoder to rerank top-k retrieved documents
query_document_pairs = [(query, doc) for doc in documents]
scores = cross_encoder.predict(query_document_pairs)
# Rank documents based on the new scores
top_k_reranked = np.argsort(scores)[-5:]
print("Top 5 reranked documents:", [documents[i] for i in top_k_reranked])
Identificando gargalos: o custo da tokenização e da previsão
Durante o desenvolvimento, descobri que os estágios de tokenização e previsão estavam demorando bastante ao lidar com 1.000 relatórios com configurações padrão para transformadores de frases. Isso criou um gargalo de desempenho, especialmente porque nosso objetivo era obter respostas em tempo real.
Abaixo, criei o perfil do meu código usando o SnakeViz para visualizar as performances:
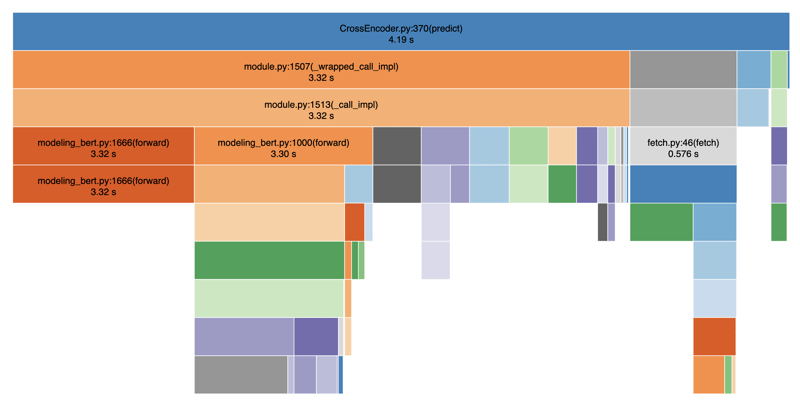
Como você pode ver, as etapas de tokenização e previsão são desproporcionalmente lentas, levando a atrasos significativos na veiculação dos resultados da pesquisa. No geral, demorou em média 4-5 segundos. Isso se deve ao fato de existirem operações de bloqueio entre as etapas de tokenização e predição. Se somarmos também outras operações como chamada de banco de dados, filtragem, etc., facilmente terminaremos com 8 a 9 segundos no total.
Otimizando o desempenho com OpenVINO
A pergunta que enfrentei foi: Podemos torná-lo mais rápido? A resposta é sim, aproveitando o OpenVINO, um back-end otimizado para inferência de CPU. OpenVINO ajuda a acelerar a inferência de modelos de aprendizagem profunda em hardware Intel, que usamos no AWS Lambda.
Exemplo de código para otimização OpenVINO
Veja como integrei o OpenVINO ao sistema de pesquisa para acelerar a inferência:
import argparse
import numpy as np
import pandas as pd
from typing import Any
from openvino.runtime import Core
from transformers import AutoTokenizer
def load_openvino_model(model_path: str) -> Core:
core = Core()
model = core.read_model(model_path ".xml")
compiled_model = core.compile_model(model, "CPU")
return compiled_model
def rerank(
compiled_model: Core,
query: str,
results: list[str],
tokenizer: AutoTokenizer,
batch_size: int,
) -> np.ndarray[np.float32, Any]:
max_length = 512
all_logits = []
# Split results into batches
for i in range(0, len(results), batch_size):
batch_results = results[i : i batch_size]
inputs = tokenizer(
[(query, item) for item in batch_results],
padding=True,
truncation="longest_first",
max_length=max_length,
return_tensors="np",
)
# Extract input tensors (convert to NumPy arrays)
input_ids = inputs["input_ids"].astype(np.int32)
attention_mask = inputs["attention_mask"].astype(np.int32)
token_type_ids = inputs.get("token_type_ids", np.zeros_like(input_ids)).astype(
np.int32
)
infer_request = compiled_model.create_infer_request()
output = infer_request.infer(
{
"input_ids": input_ids,
"attention_mask": attention_mask,
"token_type_ids": token_type_ids,
}
)
logits = output["logits"]
all_logits.append(logits)
all_logits = np.concatenate(all_logits, axis=0)
return all_logits
def fetch_search_data(search_text: str) -> pd.DataFrame:
# Usually you would fetch the data from a database
df = pd.read_csv("cnbc_headlines.csv")
df = df[~df["Headlines"].isnull()]
texts = df["Headlines"].tolist()
# Load the model and rerank
openvino_model = load_openvino_model("cross-encoder-openvino-model/model")
tokenizer = AutoTokenizer.from_pretrained("cross-encoder/ms-marco-TinyBERT-L-2-v2")
rerank_scores = rerank(openvino_model, search_text, texts, tokenizer, batch_size=16)
# Add the rerank scores to the DataFrame and sort by the new scores
df["rerank_score"] = rerank_scores
df = df.sort_values(by="rerank_score", ascending=False)
return df
if __name__ == "__main__":
parser = argparse.ArgumentParser(
description="Fetch search results with reranking using OpenVINO"
)
parser.add_argument(
"--search_text",
type=str,
required=True,
help="The search text to use for reranking",
)
args = parser.parse_args()
df = fetch_search_data(args.search_text)
print(df)
Com essa abordagem, poderíamos obter uma aceleração de 2 a 3x, reduzindo os 4 a 5 segundos originais para 1 a 2 segundos. O código funcional completo está no Github.
Ajuste fino para velocidade: tamanho do lote e tokenização
Outro fator crítico para melhorar o desempenho foi otimizar o processo de tokenização e ajustar o tamanho do lote e o comprimento do token. Aumentando o tamanho do lote (batch_size=16) e reduzindo o comprimento do token (max_length=512), poderíamos paralelizar a tokenização e reduzir a sobrecarga de operações repetitivas. Em nossos experimentos, descobrimos que um batch_size entre 16 e 64 funcionou bem, com qualquer valor maior degradando o desempenho. Da mesma forma, estabelecemos um max_length de 128, o que é viável se o comprimento médio dos seus relatórios for relativamente curto. Com essas mudanças, alcançamos uma aceleração geral de 8x, reduzindo o tempo de reclassificação para menos de 1 segundo, mesmo na CPU.
Na prática, isso significava experimentar diferentes tamanhos de lote e comprimentos de token para encontrar o equilíbrio certo entre velocidade e precisão para seus dados. Ao fazer isso, observamos melhorias significativas nos tempos de resposta, tornando o sistema de pesquisa escalonável mesmo com 1.000 relatórios.
Conclusão
Ao usar o OpenVINO e otimizar a tokenização e o processamento em lote, conseguimos construir um sistema de pesquisa semântica de alto desempenho que atende aos requisitos em tempo real em uma configuração somente de CPU. Na verdade, experimentamos uma aceleração geral de 8x. A combinação de recuperação usando transformadores de frase e reclassificação com um modelo de codificação cruzada cria uma experiência de pesquisa poderosa e fácil de usar.
Se você estiver construindo sistemas semelhantes com restrições de tempo de resposta e recursos computacionais, recomendo fortemente explorar o OpenVINO e o lote inteligente para obter melhor desempenho.
Esperamos que você tenha gostado deste artigo. Se você achou este artigo útil, curta-me para que outras pessoas também possam encontrá-lo e compartilhe-o com seus amigos. Siga-me no Linkedin para ficar atualizado sobre meu trabalho. Obrigado por ler!
-
 Como posso ler com eficiência um arquivo grande em ordem inversa usando o Python?lendo um arquivo em ordem inversa em python se você estiver trabalhando com um arquivo grande e precisar ler seus conteúdos da última linha pa...Programação Postado em 2025-07-03
Como posso ler com eficiência um arquivo grande em ordem inversa usando o Python?lendo um arquivo em ordem inversa em python se você estiver trabalhando com um arquivo grande e precisar ler seus conteúdos da última linha pa...Programação Postado em 2025-07-03 -
Como converter com eficiência fusos horários em PHP?Conversão eficiente do fuso horário em php No PHP, o manuseio dos fusos horários pode ser uma tarefa direta. Este guia fornecerá um método fácil...Programação Postado em 2025-07-03
-
Por que o Microsoft Visual C ++ falha ao implementar corretamente a instanciação do modelo bifásico?O mistério do modelo de duas fases "quebrado" bifásia instanciação no Microsoft Visual C Declaração de Problema: STRAGLES Expressa...Programação Postado em 2025-07-03
-
-
Como posso manter a renderização de células JTable personalizada após a edição de células?MANAZENDO JTABLE CELUMENTE renderização após a célula edit em uma jtable, implementar capacidades de renderização e edição de células personal...Programação Postado em 2025-07-03
-
Existe uma diferença de desempenho entre usar um loop for-Each e um iterador para travessia de coleção em Java?para cada loop vs. iterator: eficiência na coleção Traversal Introduction quando travessing uma coleção em java, the ARIDES quando trave...Programação Postado em 2025-07-03
-
Como analisar números na notação exponencial usando decimal.parse ()?analisando um número da notação exponencial ao tentar analisar uma string expressa em anotação exponencial usando Decimal.parse ("1.2345e...Programação Postado em 2025-07-03
-
Por que as expressões lambda exigem variáveis "final" ou "final válida" em Java?expressões lambda requerem "final" ou "efetivamente" variáveis a mensagem de erro "BEATILE Utilizada na expressão l...Programação Postado em 2025-07-03
-
Como resolver o erro \ "Uso inválido da função do grupo \" no MySQL ao encontrar a contagem máxima?como recuperar a contagem máxima usando o mysql em mysql, você pode encontrar um problema enquanto tenta encontrar a contagem máxima de valore...Programação Postado em 2025-07-03
-
Como remover os manipuladores anônimos de eventos JavaScript de maneira limpa?removendo os ouvintes anônimos do evento adicionando ouvintes de eventos anônimos a elementos fornece flexibilidade e simplicidade, mas quando é...Programação Postado em 2025-07-03
-
Como posso selecionar programaticamente todo o texto dentro de uma div em mouse clique?selecionando programaticamente o texto div no mouse click question dado um elemento Div com conteúdo de texto, como o usuário pode selecionar ...Programação Postado em 2025-07-03
-
Como limitar o intervalo de rolagem de um elemento dentro de um elemento pai de tamanho dinâmico?implementando limites de altura CSS para elementos de rolagem vertical em uma interface interativa, o controle do comportamento de rolagem dos...Programação Postado em 2025-07-03
-
Por que as junções da esquerda parecem intra-conexões ao filtrar na cláusula onde na tabela direita?junção de partida Condrum: horas de bruxa quando se transforma em uma junção interna em um reino de um assistente de banco de dados, realizar re...Programação Postado em 2025-07-03
-
Python Metaclass Working Princípio e Criação e Personalização de ClasseO que são metaclasses em python? metaclasses são responsáveis por criar objetos de classe em python. Assim como as aulas criam instâncias, as ...Programação Postado em 2025-07-03
-
O Java permite vários tipos de retorno: uma olhada mais próxima dos métodos genéricos?Tipos de retorno múltiplos em java: um equívoco revelado no reino da programação java, e um método peculiar pode surgir, deixando os desenvolv...Programação Postado em 2025-07-03















Estude chinês
- 1 Como se diz “andar” em chinês? 走路 Pronúncia chinesa, 走路 aprendizagem chinesa
- 2 Como se diz “pegar um avião” em chinês? 坐飞机 Pronúncia chinesa, 坐飞机 aprendizagem chinesa
- 3 Como se diz “pegar um trem” em chinês? 坐火车 Pronúncia chinesa, 坐火车 aprendizagem chinesa
- 4 Como se diz “pegar um ônibus” em chinês? 坐车 Pronúncia chinesa, 坐车 aprendizagem chinesa
- 5 Como se diz dirigir em chinês? 开车 Pronúncia chinesa, 开车 aprendizagem chinesa
- 6 Como se diz nadar em chinês? 游泳 Pronúncia chinesa, 游泳 aprendizagem chinesa
- 7 Como se diz andar de bicicleta em chinês? 骑自行车 Pronúncia chinesa, 骑自行车 aprendizagem chinesa
- 8 Como você diz olá em chinês? 你好Pronúncia chinesa, 你好Aprendizagem chinesa
- 9 Como você agradece em chinês? 谢谢Pronúncia chinesa, 谢谢Aprendizagem chinesa
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









