
주어진 스택에서 중복을 제거하는 Java 프로그램
 검색:627
검색:627
이 문서에서는 Java의 스택에서 중복 요소를 제거하는 두 가지 방법을 살펴보겠습니다. 중첩 루프를 사용한 간단한 접근 방식과 HashSet을 사용하는 보다 효율적인 방법을 비교해 보겠습니다. 목표는 중복 제거를 최적화하는 방법을 보여주고 각 접근 방식의 성능을 평가하는 것입니다.
문제 설명
스택에서 중복된 요소를 제거하는 Java 프로그램을 작성하세요.
입력
Stackdata = initData(10L);
산출
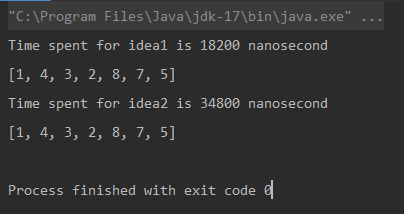
Unique elements using Naive Approach: [1, 4, 3, 2, 8, 7, 5] Time spent for Naive Approach: 18200 nanoseconds Unique elements using Optimized Approach: [1, 4, 3, 2, 8, 7, 5] Time spent for Optimized Approach: 34800 nanoseconds
주어진 스택에서 중복 항목을 제거하려면 2가지 접근 방식이 있습니다. -
- 순진한 접근 방식: 두 개의 중첩 루프를 만들어 어떤 요소가 이미 존재하는지 확인하고 해당 요소가 결과 스택 반환에 추가되지 않도록 합니다.
- HashSet 접근 방식: Set을 사용하여 고유한 요소를 저장하고 O(1) 복잡성을 활용하여 요소가 있는지 여부를 확인합니다.
임의 스택 생성 및 복제
아래는 Java 프로그램이 먼저 임의의 스택을 구축한 다음 추가 사용을 위해 복제본을 생성하는 것입니다. -
private static Stack initData(Long size) {
Stack stack = new Stack ();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i manualCloneStack(Stack stack) {
Stack newStack = new Stack ();
for (Integer item: stack) {
newStack.push(item);
}
return newStack;
}
initData 는 지정된 크기와 1~100 범위의 임의 요소로 스택을 생성하는 데 도움이 됩니다.
manualCloneStack 는 다른 스택에서 데이터를 복사하여 데이터를 생성하고 이를 두 아이디어 간의 성능 비교에 사용하는 데 도움이 됩니다.
순진한 접근 방식을 사용하여 특정 스택에서 중복 항목 제거
다음은 Naïve 접근 방식을 사용하여 특정 스택에서 중복 항목을 제거하는 단계입니다. -
- 타이머를 시작합니다.
- 고유한 요소를 저장할 빈 스택을 만듭니다.
- while 루프를 사용하여 반복하고 원래 스택이 비어 있을 때까지 계속해서 최상위 요소를 팝합니다.
- 요소가 이미 결과 스택에 있는지 확인하려면 resultStack.contains(element)를 사용하여 중복 항목을 확인하세요.
- 요소가 결과 스택에 없으면 결과 스택에 추가합니다.
- 종료 시간을 기록하고 소요된 총 시간을 계산합니다.
- 결과 반환
예
다음은 Naïve 접근 방식을 사용하여 주어진 스택에서 중복 항목을 제거하는 Java 프로그램입니다. -
public static Stack idea1(Stack stack) {
long start = System.nanoTime();
Stack resultStack = new Stack ();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!resultStack.contains(element)) {
resultStack.add(element);
}
}
System.out.println("Time spent for idea1 is %d nanosecond".formatted(System.nanoTime() - start));
return resultStack;
}
순진한 접근 방식에는
를 사용합니다.while (!stack.isEmpty())입니다.
resultStack.contains(element)
요소가 이미 존재하는지 확인합니다.최적화된 접근 방식(HashSet)을 사용하여 지정된 스택에서 중복 항목을 제거합니다.
다음은 최적화된 접근 방식을 사용하여 특정 스택에서 중복 항목을 제거하는 단계입니다. -
- 타이머 시작
- 본 요소를 추적하기 위한 세트를 만듭니다(O(1) 복잡성 검사의 경우).
- 고유한 요소를 저장하기 위한 임시 스택을 만듭니다.
- 스택이 빌 때까지 while 루프를 사용하여 반복합니다.
- 스택에서 최상위 요소를 제거합니다.
- 중복을 확인하기 위해 seen.contains(element)를 사용하여 요소가 이미 세트에 있는지 확인합니다.
- 요소가 세트에 없으면 표시된 스택과 임시 스택에 모두 추가합니다.
- 종료 시간을 기록하고 소요된 총 시간을 계산합니다.
- 결과 반환
예
다음은 HashSet -
를 사용하여 주어진 스택에서 중복 항목을 제거하는 Java 프로그램입니다.public static Stackidea2(Stack stack) { long start = System.nanoTime(); Set seen = new HashSet(); Stack tempStack = new Stack(); while (!stack.isEmpty()) { int element = stack.pop(); if (!seen.contains(element)) { seen.add(element); tempStack.push(element); } } System.out.println("Time spent for idea2 is %d nanosecond".formatted(System.nanoTime() - start)); return tempStack; }
최적화된 접근 방식을 위해
를 사용합니다.Set seen 두 가지 접근 방식을 함께 사용
다음은 위에서 언급한 두 가지 접근 방식을 사용하여 특정 스택에서 중복 항목을 제거하는 단계입니다.
- initData(Long size) 메서드를 사용하여 데이터를 초기화하여 임의의 정수로 채워진 스택을 만듭니다.
- cloneStack(스택 스택) 메서드를 사용하여 원본 스택의 정확한 복사본을 생성하는 스택을 복제합니다.
- initData를 사용하여 초기 스택을 생성합니다.
- cloneStack을 사용하여 이 스택을 복제합니다.
- 원본 스택에서 중복 항목을 제거하려면 순진한 접근 방식을 적용하세요.
- 복제된 스택에서 중복 항목을 제거하려면 최적화된 접근 방식을 적용하세요.
- 각 방법에 소요된 시간과 두 가지 접근 방식으로 생성된 고유 요소를 표시합니다.
예
다음은 위에 언급된 두 접근 방식을 모두 사용하여 스택에서 중복 요소를 제거하는 Java 프로그램입니다.
import java.util.HashSet;
import java.util.Random;
import java.util.Set;
import java.util.Stack;
public class DuplicateStackElements {
private static Stack initData(Long size) {
Stack stack = new Stack();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i cloneStack(Stack stack) {
Stack newStack = new Stack();
newStack.addAll(stack);
return newStack;
}
public static Stack idea1(Stack stack) {
long start = System.nanoTime();
Stack resultStack = new Stack();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!resultStack.contains(element)) {
resultStack.add(element);
}
}
System.out.printf("Time spent for idea1 is %d nanoseconds%n", System.nanoTime() - start);
return resultStack;
}
public static Stack idea2(Stack stack) {
long start = System.nanoTime();
Set seen = new HashSet();
Stack tempStack = new Stack();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!seen.contains(element)) {
seen.add(element);
tempStack.push(element);
}
}
System.out.printf("Time spent for idea2 is %d nanoseconds%n", System.nanoTime() - start);
return tempStack;
}
public static void main(String[] args) {
Stack data1 = initData(10L);
Stack data2 = cloneStack(data1);
System.out.println("Unique elements using idea1: " idea1(data1));
System.out.println("Unique elements using idea2: " idea2(data2));
}
}
산출
비교
* 측정 단위는 나노초입니다.
public static void main(String[] args) {
Stack data1 = initData();
Stack data2 = manualCloneStack(data1);
idea1(data1);
idea2(data2);
}
| 방법 | 100개 요소 | 1000개 요소 | 요소 10000개 |
요소 100000개 |
요소 1000000개 |
| 아이디어 1 | 693100 |
4051600 |
19026900 |
114201800 |
1157256000 |
| 아이디어 2 | 135800 |
681400 |
2717800 |
11489400 |
36456100 |
관찰한 바와 같이, 아이디어 1의 복잡성은 O(n²)인 반면 아이디어 2의 복잡성은 O(n)이기 때문에 아이디어 2의 실행 시간은 아이디어 1보다 짧습니다. 그래서 스택 수가 늘어나면 그에 따라 계산에 소요되는 시간도 늘어납니다.
-
 Java는 여러 반환 유형을 허용합니까 : 일반적인 방법을 자세히 살펴보십시오.public 목록 getResult (문자열 s); 여기서 foo는 사용자 정의 클래스입니다. 이 방법 선언은 두 가지 반환 유형을 자랑하는 것처럼 보입니다. 목록과 E. 그러나 이것이 사실인가? 일반 방법 : 미스터리 메소드는 단일...프로그램 작성 2025-05-30에 게시되었습니다
Java는 여러 반환 유형을 허용합니까 : 일반적인 방법을 자세히 살펴보십시오.public 목록 getResult (문자열 s); 여기서 foo는 사용자 정의 클래스입니다. 이 방법 선언은 두 가지 반환 유형을 자랑하는 것처럼 보입니다. 목록과 E. 그러나 이것이 사실인가? 일반 방법 : 미스터리 메소드는 단일...프로그램 작성 2025-05-30에 게시되었습니다 -
PYTZ가 처음에 예상치 못한 시간대 오프셋을 표시하는 이유는 무엇입니까?import pytz pytz.timezone ( 'Asia/Hong_kong') std> discrepancy source 역사 전반에 걸쳐 변동합니다. PYTZ가 제공하는 기본 시간대 이름 및 오프...프로그램 작성 2025-05-30에 게시되었습니다
-
MySQL 오류 #1089 : 잘못된 접두사 키를 얻는 이유는 무엇입니까?오류 설명 [#1089- 잘못된 접두사 키 "는 테이블에서 열에 프리픽스 키를 만들려고 시도 할 때 나타날 수 있습니다. 접두사 키는 특정 접두사 길이의 문자열 열 길이를 색인화하도록 설계되었으며, 접두사를 더 빠르게 검색 할 수 있습니...프로그램 작성 2025-05-30에 게시되었습니다
-
팬더에서 연도와 1/4 열을 하나의주기적인 열로 병합하는 방법은 무엇입니까?새로운 기간 열에 대한 열을 연결하는 열 문제 문 : 라는 열이있는 pandas dataframe을 고려하십시오 : 분기 2000 Q2 2001 Q3 목표는 다음과 같은 결과를 얻기 위해 "연도"...프로그램 작성 2025-05-30에 게시되었습니다
-
두 날짜 사이의 일 수를 계산하는 JavaScript 방법const date1 = 새로운 날짜 ( '7/13/2010'); const date2 = new 날짜 ('12/15/2010 '); const difftime = math.abs (date2 -date1); const diff...프로그램 작성 2025-05-30에 게시되었습니다
-
FormData ()로 여러 파일 업로드를 처리하려면 어떻게해야합니까?); 그러나이 코드는 첫 번째 선택된 파일 만 처리합니다. 파일 : var files = document.getElementById ( 'filetOUpload'). 파일; for (var x = 0; x프로그램 작성 2025-05-29에 게시되었습니다
-
MySQL 데이터베이스 메소드는 동일한 인스턴스를 덤프 할 필요가 없습니다.직접 배관 데이터 mysql 클라이언트의 출력을 직접 배관 할 수있는 메소드 : mysqldump --routines --triggers db_name | mysql new_db_name | mysql new_db_name 이 명령은 n...프로그램 작성 2025-05-29에 게시되었습니다
-
Homebrew에서 GO를 설정하면 명령 줄 실행 문제가 발생하는 이유는 무엇입니까?발생하는 문제를 해결하려면 다음 단계를 따르십시오. 1. 필요한 디렉토리 만들기 mkdir $ home/go mkdir -p $ home/go/src/github.com/user 2. 환경 변수 구성프로그램 작성 2025-05-29에 게시되었습니다
-
PostgreSQL의 각 고유 식별자에 대한 마지막 행을 효율적으로 검색하는 방법은 무엇입니까?postgresql : 각각의 고유 식별자에 대한 마지막 행을 추출하는 select distinct on (id) id, date, another_info from the_table order by id, date desc; id ...프로그램 작성 2025-05-29에 게시되었습니다
-
순수한 CS로 여러 끈적 끈적한 요소를 서로 쌓을 수 있습니까?순수한 CSS에서 서로 위에 여러 개의 끈적 끈적 요소가 쌓일 수 있습니까? 원하는 동작을 볼 수 있습니다. 여기 : https://webthemez.com/demo/sticky-multi-header-scroll/index.html Java...프로그램 작성 2025-05-29에 게시되었습니다
-
regex를 사용하여 PHP에서 괄호 안에서 텍스트를 추출하는 방법$ fullstring = "이 (텍스트)을 제외한 모든 것을 무시하는 것"; $ start = strpos ( ', $ fullstring); $ fullString); $ shortstring = substr ($ fulls...프로그램 작성 2025-05-29에 게시되었습니다
-
오른쪽 테이블의 where 조항에서 필터링 할 때 왼쪽 결합이 연결된 이유는 무엇입니까?다음 쿼리를 상상해보십시오 : select A.Foo, B. 바, c.foobar a로 테이블온에서 내부는 a.pk = b.fk에서 b로 tabletwo를 결합합니다 b.pk = c.fk에서 c as c로 왼쪽으로 결합하십시오 여기서 a.foo = '...프로그램 작성 2025-05-29에 게시되었습니다
-
Google API에서 최신 JQuery 라이브러리를 검색하는 방법은 무엇입니까?https://code.jquery.com/jquery-latest.min.js (jQuery Hosted, Minified) https://code.jquery.com/jquery-latest.js (JQuery Hosted, Hosted, 비 압축) 압축...프로그램 작성 2025-05-29에 게시되었습니다
-
버전 5.6.5 이전에 MySQL의 Timestamp 열을 사용하여 current_timestamp를 사용하는 데 제한 사항은 무엇입니까?5.6.5 이전에 mysql 버전의 기본적으로 또는 업데이트 클로즈가있는 타임 스탬프 열의 제한 사항 5.6.5 5.6.5 이전에 mySQL 버전에서 Timestamp Holumn에 전적으로 기본적으로 한 제한 사항이 있었는데, 이는 제한적으로 전혀 ...프로그램 작성 2025-05-29에 게시되었습니다
-
Point-In-Polygon 감지에 더 효율적인 방법 : Ray Tracing 또는 Matplotlib \ 's Path.contains_points?Ray Tracing MethodThe ray tracing method intersects a horizontal ray from the point under examination with the polygon's sides. 교차로의 수를 계산하고 지점이 패...프로그램 작성 2025-05-29에 게시되었습니다















중국어 공부
- 1 "걷다"를 중국어로 어떻게 말하나요? 走路 중국어 발음, 走路 중국어 학습
- 2 "비행기를 타다"를 중국어로 어떻게 말하나요? 坐飞机 중국어 발음, 坐飞机 중국어 학습
- 3 "기차를 타다"를 중국어로 어떻게 말하나요? 坐火车 중국어 발음, 坐火车 중국어 학습
- 4 "버스를 타다"를 중국어로 어떻게 말하나요? 坐车 중국어 발음, 坐车 중국어 학습
- 5 운전을 중국어로 어떻게 말하나요? 开车 중국어 발음, 开车 중국어 학습
- 6 수영을 중국어로 뭐라고 하나요? 游泳 중국어 발음, 游泳 중국어 학습
- 7 자전거를 타다 중국어로 뭐라고 하나요? 骑自行车 중국어 발음, 骑自行车 중국어 학습
- 8 중국어로 안녕하세요를 어떻게 말해요? 你好중국어 발음, 你好중국어 학습
- 9 감사합니다를 중국어로 어떻게 말하나요? 谢谢중국어 발음, 谢谢중국어 학습
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









