 मुखपृष्ठ > प्रोग्रामिंग > वेब स्क्रैपिंग को अनुकूलित करना: JSDOM का उपयोग करके प्रमाणीकरण डेटा को स्क्रैप करना
मुखपृष्ठ > प्रोग्रामिंग > वेब स्क्रैपिंग को अनुकूलित करना: JSDOM का उपयोग करके प्रमाणीकरण डेटा को स्क्रैप करना
वेब स्क्रैपिंग को अनुकूलित करना: JSDOM का उपयोग करके प्रमाणीकरण डेटा को स्क्रैप करना
 ब्राउज़ करें:692
ब्राउज़ करें:692
स्क्रैपिंग डेवलपर्स के रूप में, हमें कभी-कभी अपने कार्यों को करने के लिए अस्थायी कुंजी जैसे प्रमाणीकरण डेटा निकालने की आवश्यकता होती है। हालाँकि, यह उतना सरल नहीं है। आमतौर पर, यह HTML या XHR नेटवर्क अनुरोधों में होता है, लेकिन कभी-कभी, प्रमाणीकरण डेटा की गणना की जाती है। उस स्थिति में, हम या तो गणना को रिवर्स-इंजीनियर कर सकते हैं, जिसमें स्क्रिप्ट को समझने में बहुत समय लगता है या इसकी गणना करने वाली जावास्क्रिप्ट को चला सकते हैं। आम तौर पर, हम ब्राउज़र का उपयोग करते हैं, लेकिन वह महंगा है। क्रॉली ब्राउज़र स्क्रैपर और चीयरियो स्क्रैपर को समानांतर में चलाने के लिए समर्थन प्रदान करता है, लेकिन यह गणना संसाधन उपयोग के मामले में बहुत जटिल और महंगा है। JSDOM हमें ब्राउज़र की तुलना में कम संसाधनों और चीयरियो की तुलना में थोड़े अधिक संसाधनों के साथ पेज जावास्क्रिप्ट चलाने में मदद करता है।
यह लेख एक नए दृष्टिकोण पर चर्चा करेगा जिसका उपयोग हम अपने एक अभिनेता में ब्राउज़र वेब अनुप्रयोगों द्वारा उत्पन्न टिकटॉक विज्ञापन रचनात्मक केंद्र से प्रमाणीकरण डेटा प्राप्त करने के लिए करते हैं, वास्तव में ब्राउज़र को चलाने के बिना, बल्कि इसके बजाय, JSDOM का उपयोग करते हुए।
वेबसाइट का विश्लेषण किया जा रहा है
जब आप इस यूआरएल पर जाते हैं:
https://ads.tiktok.com/business/creativecenter/inspire/popular/hashtag/pc/en
आपको हैशटैग की एक सूची उनकी लाइव रैंकिंग, उनके पोस्ट की संख्या, ट्रेंड चार्ट, क्रिएटर्स और एनालिटिक्स के साथ दिखाई देगी। आप यह भी देख सकते हैं कि हम उद्योग को फ़िल्टर कर सकते हैं, समय अवधि निर्धारित कर सकते हैं, और फ़िल्टर करने के लिए चेक बॉक्स का उपयोग कर सकते हैं कि शीर्ष 100 में रुझान नया है या नहीं।
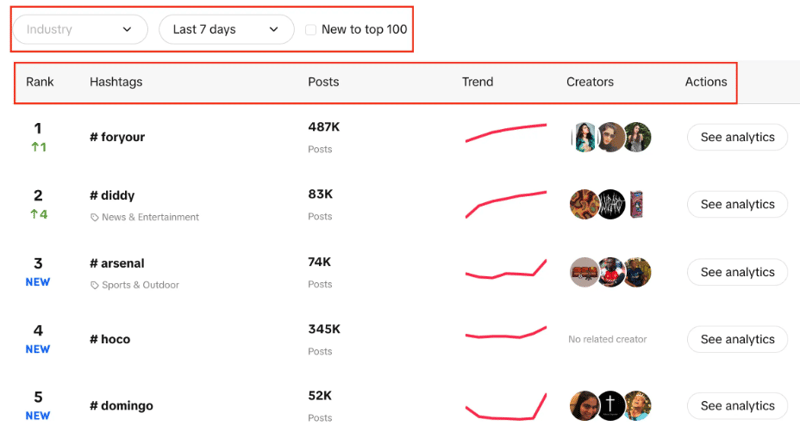
यहां हमारा लक्ष्य दिए गए फ़िल्टर के साथ सूची से शीर्ष 100 हैशटैग निकालना है।
दो संभावित दृष्टिकोण चीयरियोक्रॉलर का उपयोग करना है, और दूसरा ब्राउज़र-आधारित स्क्रैपिंग होगा। चीयरियो तेजी से परिणाम देता है लेकिन जावास्क्रिप्ट-रेंडर वेबसाइटों के साथ काम नहीं करता है।
चेरियो यहां सबसे अच्छा विकल्प नहीं है क्योंकि क्रिएटिव सेंटर एक वेब एप्लिकेशन है, और डेटा स्रोत एपीआई है, इसलिए हम केवल HTML संरचना में शुरू में मौजूद हैशटैग प्राप्त कर सकते हैं, लेकिन 100 में से प्रत्येक नहीं जैसा कि हमें चाहिए।
दूसरा दृष्टिकोण ब्राउज़र-आधारित स्क्रैपिंग करने के लिए पपेटियर, प्लेराइट इत्यादि जैसे पुस्तकालयों का उपयोग करना और सभी हैशटैग को स्क्रैप करने के लिए स्वचालन का उपयोग करना हो सकता है, लेकिन पिछले अनुभवों के साथ, ऐसे छोटे कार्य के लिए बहुत समय लगता है।
अब नया दृष्टिकोण आता है जिसे हमने इस प्रक्रिया को ब्राउज़र आधारित से काफी बेहतर बनाने और चीयरियोक्रॉलर आधारित क्रॉलिंग के बहुत करीब बनाने के लिए विकसित किया है।
जेएसडीओएम दृष्टिकोण
इस दृष्टिकोण पर गहराई से विचार करने से पहले, मैं इस दृष्टिकोण को विकसित करने के लिए एपिफाई में वेब ऑटोमेशन इंजीनियर एलेक्सी उडोविदचेंको को श्रेय देना चाहूंगा। उन्हें साधुवाद!
इस दृष्टिकोण में, हम आवश्यक डेटा प्राप्त करने के लिए https://ads.tiktok.com/creative_radar_api/v1/popular_trend/hashtag/list पर एपीआई कॉल करने जा रहे हैं।
इस एपीआई पर कॉल करने से पहले, हमें कुछ आवश्यक हेडर (ऑथ डेटा) की आवश्यकता होगी, इसलिए हम पहले https://ads.tiktok.com/business/creativecenter/inspire/popular/hashtag/pad पर कॉल करेंगे। /en.
हम एक फ़ंक्शन बनाकर इस दृष्टिकोण को शुरू करेंगे जो हमारे लिए एपीआई कॉल के लिए यूआरएल बनाएगा और कॉल करेगा और डेटा प्राप्त करेगा।
export const createStartUrls = (input) => {
const {
days = '7',
country = '',
resultsLimit = 100,
industry = '',
isNewToTop100,
} = input;
const filterBy = isNewToTop100 ? 'new_on_board' : '';
return [
{
url: `https://ads.tiktok.com/creative_radar_api/v1/popular_trend/hashtag/list?page=1&limit=50&period=${days}&country_code=${country}&filter_by=${filterBy}&sort_by=popular&industry_id=${industry}`,
headers: {
// required headers
},
userData: { resultsLimit },
},
];
};
उपरोक्त फ़ंक्शन में, हम एपीआई कॉल के लिए स्टार्ट यूआरएल बनाते हैं जिसमें विभिन्न पैरामीटर शामिल होते हैं जैसा कि हमने पहले बात की थी। पैरामीटर के अनुसार यूआरएल बनाने के बाद यह Creative_radar_api पर कॉल करेगा और सभी परिणाम लाएगा।
लेकिन यह तब तक काम नहीं करेगा जब तक हमें हेडर नहीं मिल जाते। तो, चलिए एक फ़ंक्शन बनाते हैं जो पहले sessionPool और proxyConfiguration का उपयोग करके एक सत्र बनाएगा।
export const createSessionFunction = async (
sessionPool,
proxyConfiguration,
) => {
const proxyUrl = await proxyConfiguration.newUrl(Math.random().toString());
const url =
'https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad/en';
// need url with data to generate token
const response = await gotScraping({ url, proxyUrl });
const headers = await getApiUrlWithVerificationToken(
response.body.toString(),
url,
);
if (!headers) {
throw new Error(`Token generation blocked`);
}
log.info(`Generated API verification headers`, Object.values(headers));
return new Session({
userData: {
headers,
},
sessionPool,
});
};
इस फ़ंक्शन में, मुख्य लक्ष्य https://ads.tiktok.com/business/creativecenter/inspire/popular/hashtag/pad/en पर कॉल करना और बदले में हेडर प्राप्त करना है। हेडर प्राप्त करने के लिए हम getApiUrlWithVerificationToken फ़ंक्शन का उपयोग कर रहे हैं।
आगे बढ़ने से पहले, मैं यह उल्लेख करना चाहता हूं कि क्रॉली मूल रूप से JSDOM क्रॉलर का उपयोग करके JSDOM का समर्थन करता है। यह सादे HTTP अनुरोधों और jsdom DOM कार्यान्वयन का उपयोग करके वेब पेजों के समानांतर क्रॉलिंग के लिए एक रूपरेखा देता है। यह वेब पेजों को डाउनलोड करने के लिए कच्चे HTTP अनुरोधों का उपयोग करता है, यह डेटा बैंडविड्थ पर बहुत तेज़ और कुशल है।
आइए देखें कि हम getApiUrlWithVerificationToken फ़ंक्शन कैसे बनाने जा रहे हैं:
const getApiUrlWithVerificationToken = async (body, url) => {
log.info(`Getting API session`);
const virtualConsole = new VirtualConsole();
const { window } = new JSDOM(body, {
url,
contentType: 'text/html',
runScripts: 'dangerously',
resources: 'usable' || new CustomResourceLoader(),
// ^ 'usable' faster than custom and works without canvas
pretendToBeVisual: false,
virtualConsole,
});
virtualConsole.on('error', () => {
// ignore errors cause by fake XMLHttpRequest
});
const apiHeaderKeys = ['anonymous-user-id', 'timestamp', 'user-sign'];
const apiValues = {};
let retries = 10;
// api calls made outside of fetch, hack below is to get URL without actual call
window.XMLHttpRequest.prototype.setRequestHeader = (name, value) => {
if (apiHeaderKeys.includes(name)) {
apiValues[name] = value;
}
if (Object.values(apiValues).length === apiHeaderKeys.length) {
retries = 0;
}
};
window.XMLHttpRequest.prototype.open = (method, urlToOpen) => {
if (
['static', 'scontent'].find((x) =>
urlToOpen.startsWith(`https://${x}`),
)
)
log.debug('urlToOpen', urlToOpen);
};
do {
await sleep(4000);
retries--;
} while (retries > 0);
await window.close();
return apiValues;
};
इस फ़ंक्शन में, हम एक वर्चुअल कंसोल बना रहे हैं जो पृष्ठभूमि प्रक्रिया को चलाने और ब्राउज़र को JSDOM से बदलने के लिए CustomResourceLoader का उपयोग करता है।
इस विशेष उदाहरण के लिए, हमें एपीआई कॉल करने के लिए तीन अनिवार्य हेडर की आवश्यकता है, और वे हैं अनाम-उपयोगकर्ता-आईडी, टाइमस्टैम्प और उपयोगकर्ता-चिह्न।
XMLHttpRequest.prototype.setRequestHeader का उपयोग करके, हम जांच कर रहे हैं कि उल्लिखित हेडर प्रतिक्रिया में हैं या नहीं, यदि हाँ, तो हम उन हेडर का मूल्य लेते हैं, और सभी हेडर प्राप्त होने तक पुनः प्रयास दोहराते हैं।
फिर, सबसे महत्वपूर्ण हिस्सा यह है कि हम प्रामाणिक डेटा निकालने और वास्तव में ब्राउज़र का उपयोग किए बिना या बॉट गतिविधि को उजागर किए बिना कॉल करने के लिए XMLHttpRequest.prototype.open का उपयोग करते हैं।createSessionFunction के अंत में, यह आवश्यक हेडर के साथ एक सत्र लौटाता है।
अब हमारे मुख्य कोड पर आते हैं, हम CheerioCrawler का उपयोग करेंगे और पिछले फ़ंक्शन से प्राप्त हेडर को requestHandler में इंजेक्ट करने के लिए प्रीनेविगेशनहुक का उपयोग करेंगे।
const crawler = new CheerioCrawler({
sessionPoolOptions: {
maxPoolSize: 1,
createSessionFunction: async (sessionPool) =>
createSessionFunction(sessionPool, proxyConfiguration),
},
preNavigationHooks: [
(crawlingContext) => {
const { request, session } = crawlingContext;
request.headers = {
...request.headers,
...session.userData?.headers,
};
},
],
proxyConfiguration,
});
अंत में अनुरोध हैंडलर में हम हेडर का उपयोग करके कॉल करते हैं और सुनिश्चित करते हैं कि सभी डेटा हैंडलिंग पेजिनेशन लाने के लिए कितनी कॉल की आवश्यकता है।
इस विशेष उदाहरण में हमने केवल एक अनुरोध और एक सत्र किया है, लेकिन यदि आपको आवश्यकता हो तो आप और भी अनुरोध कर सकते हैं। जब पहली एपीआई कॉल पूरी हो जाएगी, तो यह दूसरी एपीआई कॉल बनाएगी। फिर, यदि आवश्यक हो तो आप और कॉल कर सकते हैं, लेकिन हम दो पर रुक गए।
चीजों को और अधिक स्पष्ट करने के लिए, यहां बताया गया है कि कोड प्रवाह कैसा दिखता है:
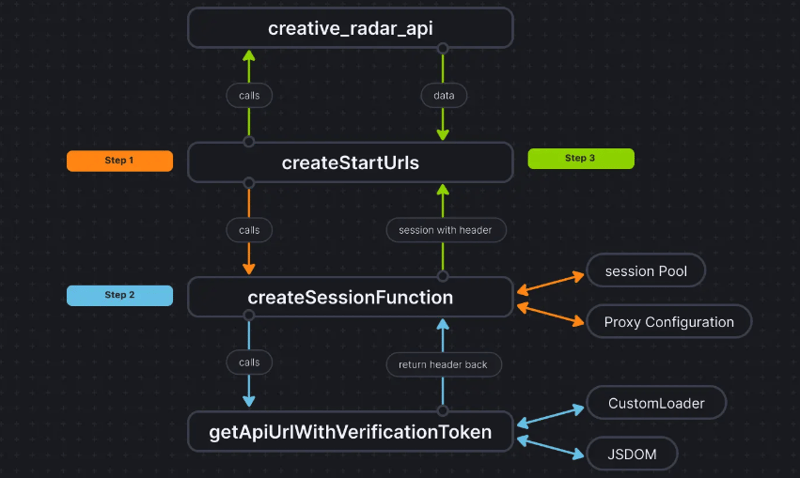
यह दृष्टिकोण हमें वास्तव में ब्राउज़र का उपयोग किए बिना प्रमाणीकरण डेटा निकालने और चीयरियोक्रॉलर को डेटा पास करने का तीसरा तरीका प्राप्त करने में मदद करता है। यह प्रदर्शन में उल्लेखनीय रूप से सुधार करता है और रैम की आवश्यकता को 50% तक कम कर देता है, और जबकि ब्राउज़र-आधारित स्क्रैपिंग प्रदर्शन शुद्ध चीयरियो की तुलना में दस गुना धीमा है, जेएसडीओएम इसे केवल 3-4 गुना धीमा करता है, जो इसे ब्राउज़र की तुलना में 2-3 गुना तेज बनाता है- आधारित स्क्रैपिंग।
परियोजना का कोडबेस पहले से ही यहां अपलोड किया गया है। कोड को Apify Actor के रूप में लिखा गया है; आप इसके बारे में यहां अधिक जानकारी पा सकते हैं, लेकिन आप इसे Apify SDK का उपयोग किए बिना भी चला सकते हैं।
यदि इस दृष्टिकोण के बारे में आपके कोई संदेह या प्रश्न हैं, तो हमारे डिस्कॉर्ड सर्वर पर हमसे संपर्क करें।
-
 मैं गो कंपाइलर में संकलन अनुकूलन को कैसे अनुकूलित कर सकता हूं?] हालाँकि, उपयोगकर्ताओं को विशिष्ट आवश्यकताओं के लिए इन अनुकूलन को समायोजित करने की आवश्यकता हो सकती है। इसका मतलब यह है कि कंपाइलर स्वचालित रूप से पू...प्रोग्रामिंग 2025-07-24 को पोस्ट किया गया
मैं गो कंपाइलर में संकलन अनुकूलन को कैसे अनुकूलित कर सकता हूं?] हालाँकि, उपयोगकर्ताओं को विशिष्ट आवश्यकताओं के लिए इन अनुकूलन को समायोजित करने की आवश्यकता हो सकती है। इसका मतलब यह है कि कंपाइलर स्वचालित रूप से पू...प्रोग्रामिंग 2025-07-24 को पोस्ट किया गया -
PHP SIMPLEXML पार्सिंग XML विधि नेमस्पेस कोलन के साथ] यह समस्या उत्पन्न होती है क्योंकि SIMPLEXML XML संरचनाओं को संभालने में असमर्थ है, जो डिफ़ॉल्ट नाम स्थान से विचलित हो जाती है। उदाहरण के लिए: $ xm...प्रोग्रामिंग 2025-07-24 को पोस्ट किया गया
-
PHP भविष्य: अनुकूलन और नवाचार] 2) प्रदर्शन और डेटा प्रोसेसिंग दक्षता में सुधार करने के लिए JIT संकलक और गणना प्रकारों का परिचय; 3) लगातार प्रदर्शन का अनुकूलन करें और सर्वोत्तम प्र...प्रोग्रामिंग 2025-07-24 को पोस्ट किया गया
-
मैं माउस क्लिक पर एक DIV के भीतर सभी पाठ का चयन कैसे कर सकता हूं?] This allows users to easily drag and drop the selected text or copy it directly.SolutionTo select the text within a DIV element on a single mouse cl...प्रोग्रामिंग 2025-07-24 को पोस्ट किया गया
-
गो में SQL प्रश्नों का निर्माण करते समय मैं सुरक्षित रूप से पाठ और मूल्यों को कैसे सहमत कर सकता हूं?] दृष्टिकोण जाने में मान्य नहीं है, और मापदंडों को कास्ट करने का प्रयास करने के लिए स्ट्रिंग्स के परिणामस्वरूप बेमेल त्रुटियां होती हैं। यह आपको रनटाइ...प्रोग्रामिंग 2025-07-24 को पोस्ट किया गया
-
PHP सरणी कुंजी-मूल्य विसंगतियाँ: 07 और 08 के जिज्ञासु मामले को समझना] PHP में, एक असामान्य मुद्दा तब उत्पन्न होता है जब कुंजियों में 07 या 08 जैसे संख्यात्मक मान होते हैं। Print_r ($ महीने) चलाना अप्रत्याशित परिणाम देत...प्रोग्रामिंग 2025-07-24 को पोस्ट किया गया
-
मान्य कोड के बावजूद PHP में इनपुट कैप्चरिंग इनपुट क्यों है?] $ _Server ['php_self']?> हालांकि, आउटपुट खाली रहता है। जबकि विधि = "प्राप्त करें" मूल रूप से काम करती है, विधि = "पोस्ट"...प्रोग्रामिंग 2025-07-24 को पोस्ट किया गया
-
वर्तमान में जावास्क्रिप्ट को निष्पादित करने वाली स्क्रिप्ट तत्व विधि का पता लगाएं] हालाँकि, दस्तावेज़ का उपयोग करने की पारंपरिक विधि। getElementsByTagName ('हेड') [0] .AppendChild (v) उपयुक्त नहीं हो सकती है यदि हेड तत्व को...प्रोग्रामिंग 2025-07-24 को पोस्ट किया गया
-
आप MySQL में डेटा को पिवट करने के लिए समूह का उपयोग कैसे कर सकते हैं?] यहाँ, हम एक सामान्य चुनौती से संपर्क करते हैं: पंक्ति-आधारित से स्तंभ-आधारित डेटा को बदलना समूह द्वारा समूह का उपयोग करके। आइए निम्न क्वेरी पर विचार...प्रोग्रामिंग 2025-07-24 को पोस्ट किया गया
-
पायथन के अनुरोधों और नकली उपयोगकर्ता एजेंटों के साथ वेबसाइट ब्लॉक को कैसे बायपास करें?] ऐसा इसलिए है क्योंकि वेबसाइटें एंटी-बॉट उपायों को लागू कर सकती हैं जो वास्तविक ब्राउज़रों और स्वचालित स्क्रिप्ट के बीच अंतर करते हैं। इन ब्लॉकों को ...प्रोग्रामिंग 2025-07-24 को पोस्ट किया गया
-
मैं पायथन का उपयोग करके रिवर्स ऑर्डर में एक बड़ी फ़ाइल को कुशलता से कैसे पढ़ सकता हूं?] इस कार्य से निपटने के लिए एक कुशल समाधान है: रिवर्स लाइन रीडर जनरेटर निम्न कोड एक जनरेटर फ़ंक्शन को परिभाषित करता है, reverse_readline, जो ए...प्रोग्रामिंग 2025-07-24 को पोस्ट किया गया
-
गो वेब एप्लिकेशन कब डेटाबेस कनेक्शन को बंद करता है?] यहाँ एक गहरी गोता है कि कब और कैसे इसे अनिश्चित काल तक चलने वाले अनुप्रयोगों में संभालना है। func मुख्य () { var इर त्रुटि DB, ERR = SQL.OPE...प्रोग्रामिंग 2025-07-24 को पोस्ट किया गया
-
MySQL में दो स्थितियों के आधार पर पंक्तियों को कुशलता से कैसे डालें या अपडेट करें?] मौजूदा पंक्ति यदि कोई मैच पाया जाता है। यह शक्तिशाली सुविधा एक नई पंक्ति सम्मिलित करके कुशल डेटा हेरफेर के लिए अनुमति देती है यदि कोई मिलान पंक्ति म...प्रोग्रामिंग 2025-07-24 को पोस्ट किया गया
-
मेरी रैखिक ढाल पृष्ठभूमि में धारियां क्यों हैं, और मैं उन्हें कैसे ठीक कर सकता हूं?] इन भद्दे कलाकृतियों को एक जटिल पृष्ठभूमि प्रसार घटना के लिए जिम्मेदार ठहराया जा सकता है। इसके बाद, रैखिक-ग्रेडिएंट इस पूरी ऊंचाई पर फैलता है, दोहराए...प्रोग्रामिंग 2025-07-24 को पोस्ट किया गया
-
UTF8 MySQL तालिका में UTF8 में Latin1 वर्णों को सही ढंग से परिवर्तित करने की विधि] "mysql_set_charset ('utf8')" कॉल करें। हालाँकि, ये विधियां पहले "अवैध" चरित्र से परे पात्रों को पकड़ने में विफल हो रही ह...प्रोग्रामिंग 2025-07-24 को पोस्ट किया गया















चीनी भाषा का अध्ययन करें
- 1 आप चीनी भाषा में "चलना" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 2 आप चीनी भाषा में "विमान ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 3 आप चीनी भाषा में "ट्रेन ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 4 आप चीनी भाषा में "बस ले लो" कैसे कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 5 चीनी भाषा में ड्राइव को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 6 तैराकी को चीनी भाषा में क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 7 आप चीनी भाषा में साइकिल चलाने को क्या कहते हैं? #का चीनी उच्चारण, #का चीनी सीखना
- 8 आप चीनी भाषा में नमस्ते कैसे कहते हैं? 你好चीनी उच्चारण, 你好चीनी सीखना
- 9 आप चीनी भाषा में धन्यवाद कैसे कहते हैं? 谢谢चीनी उच्चारण, 谢谢चीनी सीखना
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









