
Probabilistischer früher Ablauf in Go
 Durchsuche:223
Durchsuche:223
Über Cache-Stampedes
Ich komme oft in Situationen, in denen ich dieses oder jenes zwischenspeichern muss. Häufig werden diese Werte für einen bestimmten Zeitraum zwischengespeichert. Sie kennen das Muster wahrscheinlich. Sie versuchen, einen Wert aus dem Cache abzurufen. Wenn Ihnen das gelingt, geben Sie ihn an den Aufrufer zurück und beenden ihn. Wenn der Wert nicht vorhanden ist, rufen Sie ihn ab (höchstwahrscheinlich aus der Datenbank) oder berechnen ihn und legen ihn im Cache ab. In den meisten Fällen funktioniert das hervorragend. Wenn jedoch häufig auf den Schlüssel zugegriffen wird, den Sie für Ihren Cache-Eintrag verwenden, und die Berechnung der Daten eine Weile dauert, kommt es zu einer Situation, in der bei mehreren parallelen Anforderungen gleichzeitig ein Cache-Fehler auftritt. Alle diese Anfragen laden unabhängig voneinander die Quelle und speichern den Wert im Cache. Dies führt zur Verschwendung von Ressourcen und kann sogar zu einem Denial-of-Service führen.
Lassen Sie mich anhand eines Beispiels veranschaulichen. Ich verwende Redis für den Cache und einen einfachen Go-HTTP-Server darüber. Hier ist der vollständige Code:
package main
import (
"errors"
"log"
"net/http"
"time"
"github.com/redis/go-redis/v9"
)
type handler struct {
rdb *redis.Client
cacheTTL time.Duration
}
func (ch *handler) simple(w http.ResponseWriter, r *http.Request) {
cacheKey := "my_cache_key"
// we'll use 200 to signify a cache hit & 201 to signify a miss
responseCode := http.StatusOK
cachedData, err := ch.rdb.Get(r.Context(), cacheKey).Result()
if err != nil {
if !errors.Is(err, redis.Nil) {
log.Println("could not reach redis", err.Error())
http.Error(w, "could not reach redis", http.StatusInternalServerError)
return
}
// cache miss - fetch & store
res := longRunningOperation()
responseCode = http.StatusCreated
err = ch.rdb.Set(r.Context(), cacheKey, res, ch.cacheTTL).Err()
if err != nil {
log.Println("failed to set cache value", err.Error())
http.Error(w, "failed to set cache value", http.StatusInternalServerError)
return
}
cachedData = res
}
w.WriteHeader(responseCode)
_, _ = w.Write([]byte(cachedData))
}
func longRunningOperation() string {
time.Sleep(time.Millisecond * 500)
return "hello"
}
func main() {
ttl := time.Second * 3
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
})
handler := &handler{
rdb: rdb,
cacheTTL: ttl,
}
http.HandleFunc("/simple", handler.simple)
if err := http.ListenAndServe(":8080", nil); err != nil {
log.Fatalf("Could not start server: %s\n", err.Error())
}
}
Lassen Sie uns den /simple-Endpunkt etwas belasten und sehen, was passiert. Ich werde dafür Vegeta verwenden.
Ich führe vegeta attack -duration=30s -rate=500 -targets=./targets_simple.txt > res_simple.bin aus. Am Ende stellt Vegeta 30 Sekunden lang jede Sekunde 500 Anfragen. Ich stelle sie als Histogramm von HTTP-Ergebniscodes mit Buckets dar, die jeweils 100 ms umfassen. Das Ergebnis ist die folgende Grafik.

Wenn wir das Experiment starten, ist der Cache leer – wir haben dort keinen Wert gespeichert. Wir erleben den ersten Ansturm, als eine Reihe von Anfragen unseren Server erreichen. Alle überprüfen den Cache, finden dort nichts, rufen die longRunningOperation auf und speichern sie im Cache. Da die longRunningOperation ca. 500 ms benötigt, um alle in den ersten 500 ms gestellten Anforderungen abzuschließen, wird am Ende longRunningOperation aufgerufen. Sobald es einer der Anfragen gelingt, den Wert im Cache zu speichern, rufen ihn alle folgenden Anfragen aus dem Cache ab und wir sehen Antworten mit dem Statuscode 200. Das Muster wiederholt sich dann alle 3 Sekunden, wenn der Ablaufmechanismus auf Redis greift.
In diesem Spielzeugbeispiel verursacht dies keine Probleme, aber in einer Produktionsumgebung kann dies zu einer unnötigen Belastung Ihrer Systeme, einer beeinträchtigten Benutzererfahrung oder sogar einem selbstverursachten Denial-of-Service führen. Wie können wir das also verhindern? Nun, es gibt ein paar Möglichkeiten. Wir könnten eine Sperre einführen – jeder Cache-Fehler würde dazu führen, dass der Code versucht, eine Sperre zu erreichen. Verteiltes Sperren ist keine triviale Sache und oft gibt es subtile Randfälle, die eine sorgfältige Handhabung erfordern. Wir könnten den Wert auch in regelmäßigen Abständen mithilfe eines Hintergrundjobs neu berechnen. Dies erfordert jedoch die Ausführung eines zusätzlichen Prozesses, wodurch ein weiteres Rädchen entsteht, das in unserem Code verwaltet und überwacht werden muss. Dieser Ansatz ist möglicherweise auch nicht umsetzbar, wenn Sie über dynamische Cache-Schlüssel verfügen. Es gibt einen anderen Ansatz, der als probabilistischer früher Ablauf bezeichnet wird und den ich gerne weiter erforschen würde.
Probabilistischer früher Ablauf
Diese Technik ermöglicht es, den Wert basierend auf einer Wahrscheinlichkeit neu zu berechnen. Beim Abrufen des Werts aus dem Cache berechnen Sie anhand einer Wahrscheinlichkeit auch, ob Sie den Cache-Wert neu generieren müssen. Je näher Sie am Ablauf des bestehenden Wertes sind, desto höher ist die Wahrscheinlichkeit.
Ich stütze die spezifische Implementierung auf XFetch von A. Vattani, F.Chierichetti und K. Lowenstein in Optimal Probabilistic Cache Stampede Prevention.
Ich werde einen neuen Endpunkt auf dem HTTP-Server einführen, der ebenfalls die teure Berechnung durchführt, dieses Mal jedoch XFetch beim Caching verwendet. Damit XFetch funktioniert, müssen wir speichern, wie lange der teure Vorgang gedauert hat (das Delta) und wann der Cache-Schlüssel abläuft. Um das zu erreichen, führe ich eine Struktur ein, die diese Werte sowie die Nachricht selbst enthält:
type probabilisticValue struct {
Message string
Expiry time.Time
Delta time.Duration
}
Ich füge eine Funktion hinzu, um die ursprüngliche Nachricht mit diesen Attributen zu verpacken und sie zum Speichern in Redis zu serialisieren:
func wrapMessage(message string, delta, cacheTTL time.Duration) (string, error) {
bts, err := json.Marshal(probabilisticValue{
Message: message,
Delta: delta,
Expiry: time.Now().Add(cacheTTL),
})
if err != nil {
return "", fmt.Errorf("could not marshal message: %w", err)
}
return string(bts), nil
}
Lassen Sie uns auch eine Methode schreiben, um den Wert in Redis neu zu berechnen und zu speichern:
func (ch *handler) recomputeValue(ctx context.Context, cacheKey string) (string, error) {
start := time.Now()
message := longRunningOperation()
delta := time.Since(start)
wrapped, err := wrapMessage(message, delta, ch.cacheTTL)
if err != nil {
return "", fmt.Errorf("could not wrap message: %w", err)
}
err = ch.rdb.Set(ctx, cacheKey, wrapped, ch.cacheTTL).Err()
if err != nil {
return "", fmt.Errorf("could not save value: %w", err)
}
return message, nil
}
Um festzustellen, ob wir den Wert basierend auf der Wahrscheinlichkeit aktualisieren müssen, können wir probabilisticValue eine Methode hinzufügen:
func (pv probabilisticValue) shouldUpdate() bool {
// suggested default param in XFetch implementation
// if increased - results in earlier expirations
beta := 1.0
now := time.Now()
scaledGap := pv.Delta.Seconds() * beta * math.Log(rand.Float64())
return now.Sub(pv.Expiry).Seconds() >= scaledGap
}
Wenn wir alles zusammenfügen, erhalten wir den folgenden Handler:
func (ch *handler) probabilistic(w http.ResponseWriter, r *http.Request) {
cacheKey := "probabilistic_cache_key"
// we'll use 200 to signify a cache hit & 201 to signify a miss
responseCode := http.StatusOK
cachedData, err := ch.rdb.Get(r.Context(), cacheKey).Result()
if err != nil {
if !errors.Is(err, redis.Nil) {
log.Println("could not reach redis", err.Error())
http.Error(w, "could not reach redis", http.StatusInternalServerError)
return
}
res, err := ch.recomputeValue(r.Context(), cacheKey)
if err != nil {
log.Println("could not recompute value", err.Error())
http.Error(w, "could not recompute value", http.StatusInternalServerError)
return
}
responseCode = http.StatusCreated
cachedData = res
w.WriteHeader(responseCode)
_, _ = w.Write([]byte(cachedData))
return
}
pv := probabilisticValue{}
err = json.Unmarshal([]byte(cachedData), &pv)
if err != nil {
log.Println("could not unmarshal probabilistic value", err.Error())
http.Error(w, "could not unmarshal probabilistic value", http.StatusInternalServerError)
return
}
if pv.shouldUpdate() {
_, err := ch.recomputeValue(r.Context(), cacheKey)
if err != nil {
log.Println("could not recompute value", err.Error())
http.Error(w, "could not recompute value", http.StatusInternalServerError)
return
}
responseCode = http.StatusAccepted
}
w.WriteHeader(responseCode)
_, _ = w.Write([]byte(cachedData))
}
Der Handler funktioniert ähnlich wie der erste, jedoch würfeln wir, wenn wir einen Cache-Treffer erhalten. Abhängig vom Ergebnis geben wir entweder einfach den gerade abgerufenen Wert zurück oder aktualisieren den Wert vorzeitig.
Wir verwenden die HTTP-Statuscodes, um zwischen den drei Fällen zu unterscheiden:
- 200 – wir haben den Wert aus dem Cache zurückgegeben
- 201 – Cache-Fehler, kein Wert vorhanden
- 202 – Cache-Treffer, probabilistische Aktualisierung ausgelöst
Ich starte Vegeta noch einmal, diesmal gegen den neuen Endpunkt, und hier ist das Ergebnis:

Die kleinen blauen Kleckse dort zeigen an, wann wir den Cache-Wert tatsächlich vorzeitig aktualisiert haben. Nach der ersten Aufwärmphase sehen wir keine Cache-Fehler mehr. Um die anfängliche Spitze zu vermeiden, können Sie den zwischengespeicherten Wert vorab speichern, wenn dies für Ihren Anwendungsfall wichtig ist.
Wenn Sie beim Caching aggressiver vorgehen und den Wert häufiger aktualisieren möchten, können Sie mit dem Beta-Parameter experimentieren. So sieht das gleiche Experiment aus, wenn der Beta-Parameter auf 2 gesetzt ist:
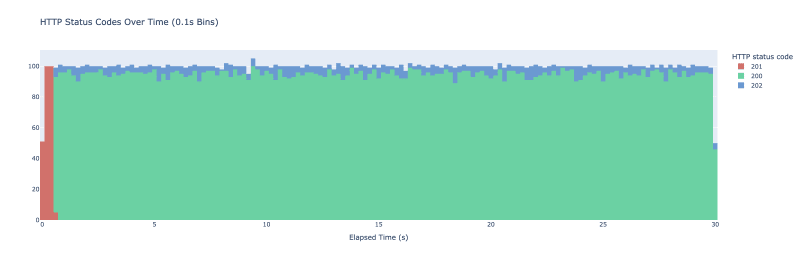
Wir sehen jetzt viel häufiger probabilistische Aktualisierungen.
Alles in allem ist dies eine nette kleine Technik, die dabei helfen kann, Cache-Stampedes zu vermeiden. Beachten Sie jedoch, dass dies nur funktioniert, wenn Sie regelmäßig denselben Schlüssel aus dem Cache abrufen. Andernfalls werden Sie keinen großen Nutzen sehen.
Haben Sie eine andere Möglichkeit, mit Cache-Stampedes umzugehen? Ist Ihnen ein Fehler aufgefallen? Lass es mich unten in den Kommentaren wissen!
-
 Was ist der Unterschied zwischen verschachtelten Funktionen und Schließungen in PythonNested Functions vs. Closures in PythonWhile nested functions in Python superficially resemble closures, they are fundamentally distinct due to a key ...Programmierung Gepostet am 2025-05-03
Was ist der Unterschied zwischen verschachtelten Funktionen und Schließungen in PythonNested Functions vs. Closures in PythonWhile nested functions in Python superficially resemble closures, they are fundamentally distinct due to a key ...Programmierung Gepostet am 2025-05-03 -
Gibt es einen Leistungsunterschied zwischen der Verwendung einer For-Each-Schleife und einem Iterator für die Sammlung durchquert in Java?für jede Schleife vs. Iterator: Effizienz in der Sammlung tRaversal Einführung beim Durchlaufen einer Sammlung in Java, die Auswahl an der...Programmierung Gepostet am 2025-05-03
-
Wie vermeiden Sie Speicherlecks beim Schneiden von Sprache?Memory Leck in Go Slices Verständnis von Speicherlecks in Go Slices kann eine Herausforderung sein. Dieser Artikel zielt darauf ab, Klarstellu...Programmierung Gepostet am 2025-05-03
-
Wie kann man Zeitzonen effizient in PHP konvertieren?effiziente Timezone -Konvertierung in php In PHP können TimeZones eine einfache Aufgabe sein. Dieser Leitfaden bietet eine leicht zu implementie...Programmierung Gepostet am 2025-05-03
-
Wie kann ich mehrere Benutzertypen (Schüler, Lehrer und Administratoren) in ihre jeweiligen Aktivitäten in einer Firebase -App umleiten?rot: Wie man mehrere Benutzertypen zu jeweiligen Aktivitäten umleitet Login. Der aktuelle Code verwaltet die Umleitung für zwei Benutzertypen erf...Programmierung Gepostet am 2025-05-03
-
Wie kann ich programmgesteuert den gesamten Text in einer DIV auf Mausklick auswählen?programmatisch den Div -Text in Maus auswählen klicken Frage angegeben ein DIV -Element mit Textinhalten, wie kann der Benutzer programmatisch...Programmierung Gepostet am 2025-05-03
-
Wie kann man leere Arrays in PHP effizient erfassen?prüfen Array -Leere in php Ein leeres Array kann in Php durch verschiedene Ansätze bestimmt werden. Wenn das Vorhandensein eines Array -Elemen...Programmierung Gepostet am 2025-05-03
-
Fastapi benutzerdefinierte 404 -Seiten -Kreationsleitfadenbenutzerdefinierte 404 nicht gefundene Seite mit fastapi um eine benutzerdefinierte Seite zu erstellen. The appropriate method depends on your...Programmierung Gepostet am 2025-05-03
-
Wie kann ich bei der Erstellung von SQL -Abfragen in Go sicher Text und Werte verkettet?concattenieren Text und Werte in Go SQL -Abfragen Bei der Erstellung eines Text -SQL -Abfrages in GO, es gibt bestimmte Syntax -Regeln, die be...Programmierung Gepostet am 2025-05-03
-
Warum nicht "Körper {Rand: 0; } `Immer den oberen Rand in CSS entfernen?adressieren die Entfernung von Körperrand in CSS Für Anfänger -Webentwickler kann das Entfernen des Randes des Körperelements eine verwirrende...Programmierung Gepostet am 2025-05-03
-
Wie erstelle ich in Python dynamische Variablen?dynamische variable Erstellung in Python Die Fähigkeit, dynamisch Variablen zu erstellen, kann ein leistungsstarkes Tool sein, insbesondere we...Programmierung Gepostet am 2025-05-03
-
Wie löste ich den Fehler "Der Dateityp nicht erraten, Anwendung/Oktett-Stream ..." in Appengine?appengine statische Datei mime type override In Appengine können statische Datei Handler gelegentlich den richtigen MIME -Typ überschreiben, w...Programmierung Gepostet am 2025-05-03
-
Zugangs- und Managementmethoden der Python -UmgebungsvariablenZugriff auf Umgebungsvariablen in Python , um auf Umgebung Variablen in Python zuzugreifen, verwenden Sie die os.environ Objekt, das ein Kapp...Programmierung Gepostet am 2025-05-03
-
Der Compiler -Fehler "usr/bin/ld: kann nicht -l" -Lösung findenDieser Fehler gibt an, dass der Linker die angegebene Bibliothek beim Verknüpfen Ihrer ausführbaren Datei nicht finden kann. Um dieses Problem z...Programmierung Gepostet am 2025-05-03
-
Wie fixiere ich \ "mysql_config, die bei der Installation von MySQL-Python auf Ubuntu/Linux nicht gefunden wurden?mySql-python-Installationsfehler: "mysql_config nicht gefunden" versuchen, mySQL-Python auf Ubuntu/Linux zu installieren. Dieser Feh...Programmierung Gepostet am 2025-05-03















Chinesisch lernen
- 1 Wie sagt man „gehen“ auf Chinesisch? 走路 Chinesische Aussprache, 走路 Chinesisch lernen
- 2 Wie sagt man auf Chinesisch „Flugzeug nehmen“? 坐飞机 Chinesische Aussprache, 坐飞机 Chinesisch lernen
- 3 Wie sagt man auf Chinesisch „einen Zug nehmen“? 坐火车 Chinesische Aussprache, 坐火车 Chinesisch lernen
- 4 Wie sagt man auf Chinesisch „Bus nehmen“? 坐车 Chinesische Aussprache, 坐车 Chinesisch lernen
- 5 Wie sagt man „Fahren“ auf Chinesisch? 开车 Chinesische Aussprache, 开车 Chinesisch lernen
- 6 Wie sagt man Schwimmen auf Chinesisch? 游泳 Chinesische Aussprache, 游泳 Chinesisch lernen
- 7 Wie sagt man auf Chinesisch „Fahrrad fahren“? 骑自行车 Chinesische Aussprache, 骑自行车 Chinesisch lernen
- 8 Wie sagt man auf Chinesisch Hallo? 你好Chinesische Aussprache, 你好Chinesisch lernen
- 9 Wie sagt man „Danke“ auf Chinesisch? 谢谢Chinesische Aussprache, 谢谢Chinesisch lernen
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









