
تحسين تجريف الويب: تجريف بيانات المصادقة باستخدام JSDOM
 تصفح:523
تصفح:523
كمطورين متخصصين، نحتاج أحيانًا إلى استخراج بيانات المصادقة مثل المفاتيح المؤقتة لأداء مهامنا. ومع ذلك، فالأمر ليس بهذه البساطة. عادةً ما يكون ذلك في طلبات شبكة HTML أو XHR، ولكن في بعض الأحيان، يتم حساب بيانات المصادقة. في هذه الحالة، يمكننا إما إجراء هندسة عكسية للعملية الحسابية، الأمر الذي يستغرق الكثير من الوقت لإزالة تشويش البرامج النصية أو تشغيل JavaScript الذي يحسبها. عادةً، نستخدم المتصفح، ولكنه مكلف. يوفر Crawlee الدعم لتشغيل مكشطة المتصفح وCheerio Scraper بالتوازي، ولكن هذا أمر معقد للغاية ومكلف من حيث استخدام موارد الحساب. يساعدنا JSDOM في تشغيل JavaScript للصفحة بموارد أقل من المتصفح وأعلى قليلاً من Cheerio.
ستناقش هذه المقالة النهج الجديد الذي نستخدمه في أحد ممثلينا للحصول على بيانات المصادقة من مركز إبداعات إعلانات TikTok التي تم إنشاؤها بواسطة تطبيقات الويب للمتصفح دون تشغيل المتصفح فعليًا ولكن بدلاً من ذلك، باستخدام JSDOM.
تحليل الموقع
عند زيارة عنوان URL هذا:
https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pc/en
سترى قائمة بعلامات التصنيف مع ترتيبها المباشر وعدد المشاركات لديها ومخطط الاتجاه والمبدعين والتحليلات. يمكنك أيضًا ملاحظة أنه يمكننا تصفية الصناعة، وتعيين الفترة الزمنية، واستخدام خانة الاختيار لتصفية ما إذا كان الاتجاه جديدًا ضمن أفضل 100 شركة أم لا.
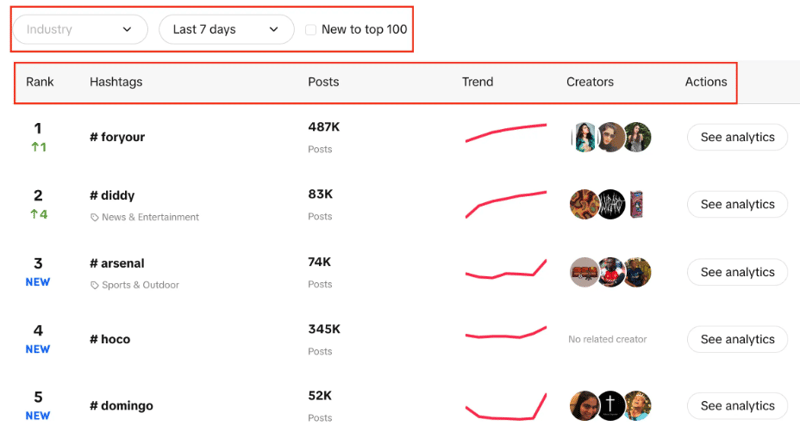
هدفنا هنا هو استخراج أفضل 100 علامة تصنيف من القائمة باستخدام المرشحات المحددة.
الطريقتان المحتملتان هما استخدام CheerioCrawler، والأسلوب الثاني سيكون الاستخراج المستند إلى المتصفح. يعطي Cheerio نتائج أسرع ولكنه لا يعمل مع مواقع الويب التي يتم عرضها بواسطة JavaScript.
لا يعد Cheerio هو الخيار الأفضل هنا نظرًا لأن Creative Center هو تطبيق ويب، ومصدر البيانات هو واجهة برمجة التطبيقات (API)، لذلك يمكننا فقط الحصول على علامات التصنيف الموجودة في البداية في بنية HTML ولكن ليس كل علامة من الـ 100 كما نطلب.
يمكن أن يكون النهج الثاني هو استخدام مكتبات مثل Puppeteer وPlaywright وما إلى ذلك، للقيام بالتجريد المستند إلى المتصفح واستخدام الأتمتة لاستخراج جميع علامات التصنيف، ولكن مع التجارب السابقة، يستغرق الأمر الكثير من الوقت لمثل هذه المهمة الصغيرة.
الآن يأتي النهج الجديد الذي قمنا بتطويره لجعل هذه العملية أفضل بكثير من المعتمدة على المتصفح وقريبة جدًا من الزحف المعتمد على CheerioCrawler.
نهج JSDOM
قبل التعمق في هذا النهج، أود أن أشيد بـ Alexey Udovydchenko، مهندس أتمتة الويب في Apify، لتطوير هذا النهج. مجد له!
في هذا النهج، سنقوم بإجراء استدعاءات واجهة برمجة التطبيقات إلى https://ads.tiktok.com/creative_radar_api/v1/popular_trend/hashtag/list للحصول على البيانات المطلوبة.
قبل إجراء استدعاءات لواجهة برمجة التطبيقات هذه، سنحتاج إلى عدد قليل من الرؤوس المطلوبة (بيانات المصادقة)، لذا سنقوم أولاً بإجراء الاتصال على https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad /ar.
سنبدأ هذا النهج من خلال إنشاء وظيفة من شأنها إنشاء عنوان URL لاستدعاء واجهة برمجة التطبيقات (API) لنا وإجراء الاتصال والحصول على البيانات.
export const createStartUrls = (input) => {
const {
days = '7',
country = '',
resultsLimit = 100,
industry = '',
isNewToTop100,
} = input;
const filterBy = isNewToTop100 ? 'new_on_board' : '';
return [
{
url: `https://ads.tiktok.com/creative_radar_api/v1/popular_trend/hashtag/list?page=1&limit=50&period=${days}&country_code=${country}&filter_by=${filterBy}&sort_by=popular&industry_id=${industry}`,
headers: {
// required headers
},
userData: { resultsLimit },
},
];
};
في الوظيفة أعلاه، نقوم بإنشاء عنوان URL للبدء لاستدعاء واجهة برمجة التطبيقات (API) الذي يتضمن معلمات مختلفة كما تحدثنا سابقًا. بعد إنشاء عنوان URL وفقًا للمعلمات، سيتم استدعاء Creative_radar_api وجلب جميع النتائج.
لكن الأمر لن ينجح حتى نحصل على الرؤوس. لذا، فلنقم بإنشاء دالة تقوم أولاً بإنشاء جلسة باستخدام sessionPool وproxyConfiguration.
export const createSessionFunction = async (
sessionPool,
proxyConfiguration,
) => {
const proxyUrl = await proxyConfiguration.newUrl(Math.random().toString());
const url =
'https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad/en';
// need url with data to generate token
const response = await gotScraping({ url, proxyUrl });
const headers = await getApiUrlWithVerificationToken(
response.body.toString(),
url,
);
if (!headers) {
throw new Error(`Token generation blocked`);
}
log.info(`Generated API verification headers`, Object.values(headers));
return new Session({
userData: {
headers,
},
sessionPool,
});
};
في هذه الوظيفة، الهدف الرئيسي هو الاتصال بـ https://ads.tiktok.com/business/creativecenter/inspiration/popular/hashtag/pad/en والحصول على رؤوس في المقابل. للحصول على الرؤوس نستخدم وظيفة getApiUrlWithVerificationToken.
قبل المضي قدمًا، أود أن أذكر أن Crawlee يدعم أصلاً JSDOM باستخدام JSDOM Crawler. إنه يوفر إطارًا للزحف المتوازي لصفحات الويب باستخدام طلبات HTTP البسيطة وتنفيذ jsdom DOM. ويستخدم طلبات HTTP الأولية لتنزيل صفحات الويب، وهو سريع جدًا وفعال في عرض النطاق الترددي للبيانات.
دعونا نرى كيف سنقوم بإنشاء وظيفة getApiUrlWithVerificationToken:
const getApiUrlWithVerificationToken = async (body, url) => {
log.info(`Getting API session`);
const virtualConsole = new VirtualConsole();
const { window } = new JSDOM(body, {
url,
contentType: 'text/html',
runScripts: 'dangerously',
resources: 'usable' || new CustomResourceLoader(),
// ^ 'usable' faster than custom and works without canvas
pretendToBeVisual: false,
virtualConsole,
});
virtualConsole.on('error', () => {
// ignore errors cause by fake XMLHttpRequest
});
const apiHeaderKeys = ['anonymous-user-id', 'timestamp', 'user-sign'];
const apiValues = {};
let retries = 10;
// api calls made outside of fetch, hack below is to get URL without actual call
window.XMLHttpRequest.prototype.setRequestHeader = (name, value) => {
if (apiHeaderKeys.includes(name)) {
apiValues[name] = value;
}
if (Object.values(apiValues).length === apiHeaderKeys.length) {
retries = 0;
}
};
window.XMLHttpRequest.prototype.open = (method, urlToOpen) => {
if (
['static', 'scontent'].find((x) =>
urlToOpen.startsWith(`https://${x}`),
)
)
log.debug('urlToOpen', urlToOpen);
};
do {
await sleep(4000);
retries--;
} while (retries > 0);
await window.close();
return apiValues;
};
في هذه الوظيفة، نقوم بإنشاء وحدة تحكم افتراضية تستخدم CustomResourceLoader لتشغيل عملية الخلفية واستبدال المتصفح بـ JSDOM.
في هذا المثال تحديدًا، نحتاج إلى ثلاثة رؤوس إلزامية لإجراء استدعاء واجهة برمجة التطبيقات، وهي معرف المستخدم المجهول، والطابع الزمني، وتوقيع المستخدم.
باستخدام XMLHttpRequest.prototype.setRequestHeader، نقوم بالتحقق مما إذا كانت الرؤوس المذكورة موجودة في الاستجابة أم لا، إذا كانت الإجابة بنعم، فإننا نأخذ قيمة تلك الرؤوس، ونكرر المحاولات حتى نحصل على جميع الرؤوس.
الجزء الأكثر أهمية هو أننا نستخدم XMLHttpRequest.prototype.open لاستخراج بيانات المصادقة وإجراء المكالمات دون استخدام المتصفحات فعليًا أو الكشف عن نشاط الروبوت.
في نهاية createSessionFunction، تقوم بإرجاع جلسة بالرؤوس المطلوبة.
الآن نأتي إلى الكود الرئيسي الخاص بنا، سوف نستخدم CheerioCrawler وسنستخدم خطافات prenavigationHooks لإدخال الرؤوس التي حصلنا عليها من الوظيفة السابقة في requestHandler.
const crawler = new CheerioCrawler({
sessionPoolOptions: {
maxPoolSize: 1,
createSessionFunction: async (sessionPool) =>
createSessionFunction(sessionPool, proxyConfiguration),
},
preNavigationHooks: [
(crawlingContext) => {
const { request, session } = crawlingContext;
request.headers = {
...request.headers,
...session.userData?.headers,
};
},
],
proxyConfiguration,
});
أخيرًا، في معالج الطلب، نقوم بإجراء الاتصال باستخدام الرؤوس والتأكد من عدد المكالمات اللازمة لجلب جميع صفحات معالجة البيانات.
async requestHandler(context) {
const { log, request, json } = context;
const { userData } = request;
const { itemsCounter = 0, resultsLimit = 0 } = userData;
if (!json.data) {
throw new Error('BLOCKED');
}
const { data } = json;
const items = data.list;
const counter = itemsCounter items.length;
const dataItems = items.slice(
0,
resultsLimit && counter > resultsLimit
? resultsLimit - itemsCounter
: undefined,
);
await context.pushData(dataItems);
const {
pagination: { page, total },
} = data;
log.info(
`Scraped ${dataItems.length} results out of ${total} from search page ${page}`,
);
const isResultsLimitNotReached =
counter
أحد الأشياء المهمة التي يجب ملاحظتها هنا هو أننا نصنع هذا الرمز بطريقة تمكننا من إجراء أي عدد من استدعاءات واجهة برمجة التطبيقات.
في هذا المثال بالذات، قمنا للتو بتقديم طلب واحد وجلسة واحدة، ولكن يمكنك تقديم المزيد إذا كنت بحاجة. عند اكتمال استدعاء API الأول، سيتم إنشاء استدعاء API الثاني. مرة أخرى، يمكنك إجراء المزيد من المكالمات إذا لزم الأمر، لكننا توقفنا عند اثنين.
لتوضيح الأمور أكثر، إليك كيفية ظهور تدفق التعليمات البرمجية:
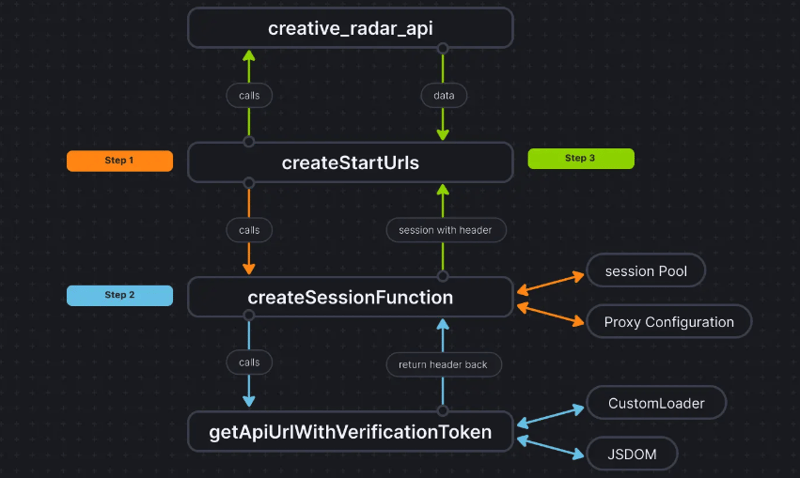
خاتمة
يساعدنا هذا الأسلوب في الحصول على طريقة ثالثة لاستخراج بيانات المصادقة دون استخدام المتصفح فعليًا وتمرير البيانات إلى CheerioCrawler. يؤدي هذا إلى تحسين الأداء بشكل كبير وتقليل متطلبات ذاكرة الوصول العشوائي بنسبة 50%، وبينما يكون أداء التجريد المستند إلى المتصفح أبطأ بعشر مرات من Cheerio النقي، فإن JSDOM يفعل ذلك أبطأ بمقدار 3-4 مرات فقط، مما يجعله أسرع 2-3 مرات من المتصفح- القشط القائم.
تم بالفعل تحميل قاعدة التعليمات البرمجية للمشروع هنا. تتم كتابة الكود كممثل Apify؛ يمكنك العثور على المزيد حول هذا الموضوع هنا، ولكن يمكنك أيضًا تشغيله دون استخدام Apify SDK.
إذا كانت لديك أي شكوك أو أسئلة حول هذا الأسلوب، تواصل معنا على خادم Discord الخاص بنا.
-
 كيفية حل الخطأ "لا يمكن تخمين نوع الملف ، واستخدام التطبيق/ثنائي الثماني ..." في AppEngine؟التطبيق/actet-stream ... " دقة مشكلة لتصحيح هذه المشكلة وتحديد نوع mime الصحيح للملفات الثابتة ، اتبع الخطوات هذه: /etc/mime.types file...برمجة نشر في 2025-05-23
كيفية حل الخطأ "لا يمكن تخمين نوع الملف ، واستخدام التطبيق/ثنائي الثماني ..." في AppEngine؟التطبيق/actet-stream ... " دقة مشكلة لتصحيح هذه المشكلة وتحديد نوع mime الصحيح للملفات الثابتة ، اتبع الخطوات هذه: /etc/mime.types file...برمجة نشر في 2025-05-23 -
كيف يمكنني تصميم المثال الأول لنوع عنصر معين عبر مستند HTML بأكمله؟مطابقة العنصر الأول من نوع معين في المستند بالكامل يمكن أن يكون التصميم الأول من نوع معين عبر مستند HTML بالكامل تحديًا باستخدام CSS وحده. يق...برمجة نشر في 2025-05-23
-
كيفية تعيين مفاتيح ديناميكي في كائنات JavaScript؟كيفية إنشاء مفتاح ديناميكي لمتغير كائن JavaScript يستخدم النهج الصحيح بين قوسين مربعين: jsObj['key' i] = 'example' 1; لتسديد خاصية مع مفتاح...برمجة نشر في 2025-05-23
-
حل الاستثناء \\ "خطأ قيمة السلسلة \\" عند إدراج MySQL Emoji'\ xf0 \ x9f \ x91 \ xbd \ xf0 \ x9f ...' ينشأ هذا الخطأ لأن حرف UTF8 الافتراضي الخاص بـ MySQL يدعم فقط الأحرف داخل المستوى متعدد اللغات....برمجة نشر في 2025-05-23
-
كيفية تحميل الملفات مع معلمات إضافية باستخدام java.net.urlconnection وترميز multipart/form-data؟فيما يلي تفصيل للعملية: multipart/form-data الترميز تم تصميم multipart/form-data لطلبات النشر التي تجمع بين كل من الثنائي (على سبيل المثال ،...برمجة نشر في 2025-05-23
-
هل يمكن أن تعتمد معلمات القالب في وظيفة C ++ 20 الإضافية على معلمات الوظيفة؟compile-time. c 20 وظائف الإضافية ومع ذلك ، يبقى السؤال: هل هذا يعني أن معلمات القالب يمكن أن تعتمد الآن على وسيطات الوظيفة؟ تقر الورقة بأن ...برمجة نشر في 2025-05-23
-
متى يغلق تطبيق الويب GO اتصال قاعدة البيانات؟إليك غوص عميق في متى وكيفية التعامل مع هذا في التطبيقات التي تعمل إلى أجل غير مسمى. المشكلة: Func Main () { var err error DB ، err = sq...برمجة نشر في 2025-05-23
-
Async void vs. Async Task in ASP.NET: لماذا ترمي طريقة الفراغ Async أحيانًا استثناءات؟ومع ذلك ، يمكن أن يؤدي سوء فهم الاختلافات الرئيسية بين أساليب المهمة ASYNC و ASYNC إلى أخطاء غير متوقعة. يستكشف هذا السؤال لماذا قد تؤدي أساليب الف...برمجة نشر في 2025-05-23
-
هل يمكنني ترحيل التشفير الخاص بي من Mcrypt إلى OpenSSL ، وفك تشفير البيانات المشفرة Mcrypt باستخدام OpenSSL؟ترقية مكتبة التشفير الخاصة بي من mcrypt إلى openssl هل يمكنني ترقية مكتبة التشفير الخاصة بي من mcrypt إلى openssl؟ في OpenSSL ، هل من الممكن ف...برمجة نشر في 2025-05-23
-
كيفية تحويل المناطق الزمنية بكفاءة في PHP؟تحويل فعال للحيوانات الزمنية في php في PHP ، يمكن أن تكون المناطق الزمنية مهمة مباشرة. سيوفر هذا الدليل طريقة سهلة التنفيذ لتحويل التواريخ والأو...برمجة نشر في 2025-05-23
-
كيفية تنفيذ الأحداث المخصصة باستخدام نمط المراقب في Java؟إنشاء أحداث مخصصة في Java لا غنى عن الأحداث المخصصة في العديد من سيناريوهات البرمجة ، مما يتيح مكونات التواصل مع بعضها البعض استنادًا إلى مشغلات...برمجة نشر في 2025-05-23
-
هل تسمح Java بأنواع عائدات متعددة: نظرة فاحصة على الطرق العامة؟أنواع عائدات متعددة في java: تم الكشف عن المفاهيم الخاطئة getResult (String s) ؛ حيث Foo فئة مخصصة. يبدو أن إعلان الطريقة يضم نوعين من الإرج...برمجة نشر في 2025-05-23
-
لماذا ينتج عن DateTime's PHP :: تعديل ('+1 شهر') نتائج غير متوقعة؟تعديل شهور مع DateTime PHP: الكشف عن السلوك المقصود عند العمل مع فئة قاعدة بيانات PHP ، قد لا تسفر عن الشهور أو طرحها دائمًا عن النتائج المتوق...برمجة نشر في 2025-05-23
-
كيفية إنشاء الرسوم المتحركة CSS اليسرى على اليسار ل div داخل الحاوية؟الرسوم المتحركة CSS عامة لحركة اليسار اليسرى في هذه المقالة ، سنستكشف إنشاء رسوم متحركة عامة لتحريك اليسار واليمين ، والوصول إلى حواف حاويةها....برمجة نشر في 2025-05-23
-
كيفية اكتشاف المصفوفات الفارغة بكفاءة في PHP؟إذا كانت الحاجة هي التحقق من وجود أي عنصر صفيف ، فإن الكتابة الفضفاضة لـ PHP تسمح بالتقييم المباشر للمصفوفة نفسها: إذا (! $ playerlist) { // ...برمجة نشر في 2025-05-23















دراسة اللغة الصينية
- 1 كيف تقول "المشي" باللغة الصينية؟ 走路 نطق الصينية، 走路 تعلم اللغة الصينية
- 2 كيف تقول "استقل طائرة" بالصينية؟ 坐飞机 نطق الصينية، 坐飞机 تعلم اللغة الصينية
- 3 كيف تقول "استقل القطار" بالصينية؟ 坐火车 نطق الصينية، 坐火车 تعلم اللغة الصينية
- 4 كيف تقول "استقل الحافلة" باللغة الصينية؟ 坐车 نطق الصينية، 坐车 تعلم اللغة الصينية
- 5 كيف أقول القيادة باللغة الصينية؟ 开车 نطق الصينية، 开车 تعلم اللغة الصينية
- 6 كيف تقول السباحة باللغة الصينية؟ 游泳 نطق الصينية، 游泳 تعلم اللغة الصينية
- 7 كيف يمكنك أن تقول ركوب الدراجة باللغة الصينية؟ 骑自行车 نطق الصينية، 骑自行车 تعلم اللغة الصينية
- 8 كيف تقول مرحبا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 9 كيف تقول شكرا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









