
كيف يجعل تحسين المقارنة عملية فرز بايثون أسرع
 تصفح:955
تصفح:955
في هذا النص، يتم استخدام مصطلحات Python وCPython، وهو التطبيق المرجعي للغة، بالتبادل. تتناول هذه المقالة CPython على وجه التحديد ولا تتعلق بأي تطبيق آخر لـ Python.
بايثون هي لغة جميلة تسمح للمبرمج بالتعبير عن أفكاره بعبارات بسيطة مع ترك تعقيد التنفيذ الفعلي وراء الكواليس.
أحد الأشياء التي يتم تجريدها هو الفرز.
يمكنك بسهولة العثور على إجابة السؤال "كيف يتم تنفيذ الفرز في بايثون؟" والذي يجيب دائمًا على سؤال آخر: "ما هي خوارزمية الفرز التي تستخدمها بايثون؟".
ومع ذلك، غالبًا ما يترك هذا بعض تفاصيل التنفيذ المثيرة للاهتمام.
هناك تفاصيل تنفيذ واحدة أعتقد أنها لم تتم مناقشتها بشكل كافٍ، على الرغم من أنها تم تقديمها منذ أكثر من سبع سنوات في بايثون 3.7:
تم تحسينsorted() وlist.sort() للحالات الشائعة لتكون أسرع بنسبة تصل إلى 40-75%. (ساهم بها إليوت جوروكوفسكي في bpo-28685.)
ولكن قبل أن نبدأ...
إعادة مقدمة موجزة للفرز في بايثون
عندما تحتاج إلى فرز قائمة في بايثون، لديك خياران:
- طريقة القائمة: list.sort(*, key=None,verse=False)، والتي تقوم بفرز القائمة المحددة في مكانها
- وظيفة مضمنة:sorted(iterable, /, *, key=None, reverse= False)، والذي يُرجع قائمة مرتبة دون تعديل الوسيطة الخاصة بها
إذا كنت بحاجة إلى فرز أي عنصر قابل للتكرار مضمن آخر، فيمكنك فقط استخدام التصنيف بغض النظر عن نوع العنصر القابل للتكرار أو المولد الذي تم تمريره كمعلمة.
يُرجع الترتيب دائمًا قائمة لأنه يستخدم list.sort داخليًا.
إليك معادل تقريبي لتطبيق CPython المصنف C الذي تمت إعادة كتابته بلغة بايثون خالصة:
def sorted(iterable: Iterable[Any], key=None, reverse=False):
new_list = list(iterable)
new_list.sort(key=key, reverse=reverse)
return new_list
نعم، الأمر بهذه البساطة.
كيف تجعل بايثون عملية الفرز أسرع
كما تقول الوثائق الداخلية للفرز في Python:
من الممكن أحيانًا استبدال مقارنات أسرع خاصة بالنوع بـ PyObject_RichCompareBool الأبطأ والعامة
وباختصار يمكن وصف هذا التحسين على النحو التالي:
عندما تكون القائمة متجانسة، تستخدم بايثون وظيفة المقارنة الخاصة بالنوع
ما هي القائمة المتجانسة؟
القائمة المتجانسة هي القائمة التي تحتوي على عناصر من نوع واحد فقط.
على سبيل المثال:
homogeneous = [1, 2, 3, 4]
من ناحية أخرى، هذه ليست قائمة متجانسة:
heterogeneous = [1, "2", (3, ), {'4': 4}]
ومن المثير للاهتمام أن البرنامج التعليمي الرسمي لبايثون ينص على ما يلي:
القوائم قابلة للتغيير، وعناصرها عادة ما تكون متجانسة ويمكن الوصول إليها عن طريق التكرار على القائمة
ملاحظة جانبية حول الصفوف
ينص هذا البرنامج التعليمي نفسه على:
الصفوف غير قابلة للتغيير، وتحتوي عادةً على تسلسل غير متجانس من العناصر
لذا، إذا تساءلت يومًا متى تستخدم صفًا أو قائمة، فإليك القاعدة الأساسية:
إذا كانت العناصر من نفس النوع، استخدم قائمة، وإلا استخدم صفًا
انتظر، وماذا عن المصفوفات؟
تنفذ بايثون كائن حاوية مصفوفة متجانسة للقيم الرقمية.
ومع ذلك، اعتبارًا من الإصدار python 3.12، لا تقوم المصفوفات بتنفيذ طريقة الفرز الخاصة بها.
الطريقة الوحيدة لفرزها هي استخدام الترتيب، الذي ينشئ قائمة من المصفوفة داخليًا، ويمسح أي معلومات متعلقة بالنوع في العملية.
لماذا يساعد استخدام وظيفة المقارنة الخاصة بالنوع؟
المقارنات في بايثون مكلفة، لأن بايثون تجري فحوصات مختلفة قبل إجراء أي مقارنة فعلية.
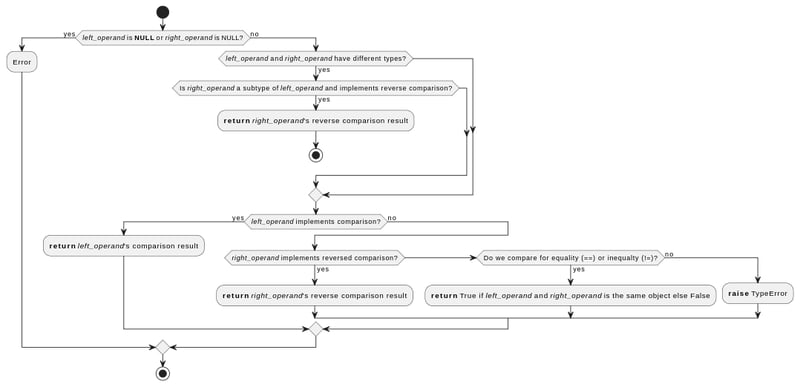
إليك شرح مبسط لما يحدث تحت الغطاء عند مقارنة قيمتين في بايثون:
- تتحقق بايثون من أن القيم التي تم تمريرها إلى وظيفة المقارنة ليست فارغة
- إذا كانت القيم من أنواع مختلفة، ولكن المعامل الأيمن هو نوع فرعي من المعامل الأيسر، تستخدم بايثون وظيفة مقارنة المعامل الأيمن، ولكن بشكل معكوس (على سبيل المثال، ستستخدم )
- إذا كانت القيم من نفس النوع، أو أنواع مختلفة ولكن لا يعد أي منهما نوعًا فرعيًا للآخر:
- سيحاول بايثون أولاً وظيفة مقارنة المعامل الأيسر
- إذا فشل ذلك، فسيتم تجربة وظيفة مقارنة المعامل الصحيح، ولكن سيتم العكس.
- إذا فشل ذلك أيضًا، وكانت المقارنة للمساواة أو عدم المساواة، فسوف تُرجع مقارنة الهوية (صحيح للقيم التي تشير إلى نفس الكائن في الذاكرة)
- وإلا فإنه يؤدي إلى ظهور TypeError
علاوة على ذلك، تقوم وظائف المقارنة الخاصة بكل نوع بتنفيذ فحوصات إضافية.
على سبيل المثال، عند مقارنة السلاسل، ستتحقق بايثون مما إذا كانت أحرف السلسلة تشغل أكثر من بايت واحد من الذاكرة، وستقوم المقارنة العائمة بمقارنة زوج من float وfloat وint بشكل مختلف.
يمكن العثور على شرح ومخطط أكثر تفصيلاً هنا: إضافة تحسينات فرز البيانات المدركة إلى CPython
قبل تقديم هذا التحسين، كان على بايثون تنفيذ كل هذه الاختبارات المتنوعة الخاصة بالنوع وغير الخاصة بالنوع في كل مرة تتم فيها مقارنة قيمتين أثناء الفرز.
التحقق من أنواع عناصر القائمة مقدمًا
لا توجد طريقة سحرية لمعرفة ما إذا كانت جميع عناصر القائمة من نفس النوع بخلاف التكرار على القائمة والتحقق من كل عنصر.
يقوم بايثون بذلك تقريبًا - التحقق من أنواع مفاتيح الفرز التي تم إنشاؤها بواسطة وظيفة المفتاح التي تم تمريرها إلى list.sort أو فرزها كمعلمة
بناء قائمة المفاتيح
إذا تم توفير وظيفة رئيسية، فإن بايثون تستخدمها لإنشاء قائمة من المفاتيح، وإلا فإنها تستخدم قيم القائمة الخاصة كمفاتيح فرز.
بطريقة مبسطة، يمكن التعبير عن بناء المفاتيح على شكل كود بايثون التالي.
if key is None:
keys = list_items
else:
keys = [key(list_item) for list_item in list_item]
لاحظ أن المفاتيح المستخدمة داخليًا في CPython هي مصفوفة C من مراجع كائنات CPython، وليست قائمة Python
بمجرد إنشاء المفاتيح، تقوم بايثون بالتحقق من أنواعها.
التحقق من نوع المفتاح
عند التحقق من أنواع المفاتيح، تحاول خوارزمية الفرز في بايثون تحديد ما إذا كانت جميع العناصر في مصفوفة المفاتيح إما str أو int أو float أو tuple، أو ببساطة من نفس النوع، مع بعض القيود على الأنواع الأساسية.
تجدر الإشارة إلى أن التحقق من أنواع المفاتيح يضيف بعض العمل الإضافي مقدمًا. تفعل بايثون هذا لأنها عادة ما تؤتي ثمارها من خلال جعل الفرز الفعلي أسرع، خاصة بالنسبة للقوائم الطويلة.
القيود كثافة العمليات
يعني هذا عمليًا أنه لكي ينجح هذا التحسين، يجب أن يكون العدد الصحيح أقل منيجب أن لا يكون عددًا كبيرًا
2^30 - 1 (قد يختلف هذا اعتمادًا على النظام الأساسي)
كملاحظة جانبية، إليك مقالة رائعة تشرح كيفية تعامل بايثون مع الأعداد الصحيحة الكبيرة: # كيف تنفذ بايثون الأعداد الصحيحة الطويلة جدًا؟قيود شارع
يجب أن تأخذ جميع أحرف السلسلة أقل من 1 بايت من الذاكرة، مما يعني أنه يجب تمثيلها بقيم عددية في النطاق من 0 إلى 255عمليا، هذا يعني أن السلاسل يجب أن تتكون فقط من الأحرف اللاتينية، والمسافات، وبعض الأحرف الخاصة الموجودة في جدول ASCII.
قيود تعويم
لا توجد قيود على العوامات لكي يعمل هذا التحسين.
قيود الصفوف
- يتم تحديد نوع العنصر الأول فقط
- لا ينبغي أن يكون هذا العنصر نفسه صفًا بحد ذاته
- إذا كانت جميع المجموعات تشترك في نفس النوع لعنصرها الأول، فسيتم تطبيق تحسين المقارنة عليها
- تتم مقارنة جميع العناصر الأخرى كالمعتاد
أولاً، أليس من الرائع أن نعرف؟
ثانيًا، قد يكون ذكر هذه المعرفة بمثابة لمسة لطيفة في مقابلة مطور بايثون.
أما بالنسبة للتطوير الفعلي للتعليمات البرمجية، فإن فهم هذا التحسين يمكن أن يساعدك على تحسين أداء الفرز.
قم بالتحسين عن طريق تحديد نوع القيم بحكمة
وفقًا للمعايير في العلاقات العامة التي قدمت هذا التحسين، فإن فرز القائمة التي تتكون من عوامات فقط بدلاً من قائمة من العوامات التي تحتوي على عدد صحيح واحد في النهاية يكون أسرع مرتين تقريبًا.
لذا عندما يحين وقت التحسين، قم بتحويل القائمة مثل هذه
floats_and_int = [1.0, -1.0, -0.5, 3]في القائمة التي تبدو هكذا
floats_and_int = [1.0, -1.0, -0.5, 3]قد يؤدي إلى تحسين الأداء.
قم بالتحسين باستخدام المفاتيح لقوائم الكائنات
بينما يعمل تحسين الفرز في Python بشكل جيد مع الأنواع المضمنة، فمن المهم فهم كيفية تفاعله مع الفئات المخصصة.
عند فرز كائنات من فئات مخصصة، تعتمد بايثون على طرق المقارنة التي تحددها، مثل __lt__ (أقل من) أو __gt__ (أكبر من).
ومع ذلك، لا ينطبق التحسين الخاص بالنوع على الفئات المخصصة.
ستستخدم بايثون دائمًا طريقة المقارنة العامة لهذه الكائنات.
إذا كان الأداء أمرًا بالغ الأهمية عند فرز الكائنات المخصصة، ففكر في استخدام وظيفة رئيسية تُرجع نوعًا مضمنًا:
floats_and_int = [1.0, -1.0, -0.5, 3]خاتمة
التحسين المبكر، خاصة في بايثون، هو أمر شرير.
لا يجب عليك تصميم تطبيقك بالكامل حول تحسينات محددة في CPython، ولكن من الجيد أن تكون على دراية بهذه التحسينات: معرفة أدواتك جيدًا هي وسيلة لتصبح مطورًا أكثر مهارة.
يسمح لك الانتباه إلى مثل هذه التحسينات بالاستفادة منها عندما يستدعي الموقف ذلك، خاصة عندما يصبح الأداء حرجًا:
فكر في سيناريو حيث كان الفرز الخاص بك يعتمد على الطوابع الزمنية: استخدام قائمة متجانسة من الأعداد الصحيحة (الطوابع الزمنية لنظام Unix) بدلاً من كائنات التاريخ والوقت يمكن أن يؤدي إلى الاستفادة من هذا التحسين بشكل فعال.
ومع ذلك، من المهم أن تتذكر أن سهولة قراءة التعليمات البرمجية وقابلية صيانتها يجب أن تكون لها الأولوية على مثل هذه التحسينات.
في حين أنه من المهم معرفة هذه التفاصيل ذات المستوى المنخفض، فمن المهم أيضًا تقدير تجريدات بايثون عالية المستوى التي تجعلها لغة منتجة.
بايثون هي لغة مذهلة، واستكشاف أعماقها يمكن أن يساعدك على فهمها بشكل أفضل وتصبح مبرمج بايثون أفضل.
-
 مستخدم تنسيق الوقت المحلي ودليل عرض إزاحة المنطقة الزمنيةعرض التاريخ/الوقت في تنسيق لغة المستخدم مع إزاحة الوقت عند تقديم التواريخ والأوقات إلى المستخدمين النهائيين ، من الأهمية بمكان عرضها في الوقت ...برمجة نشر في 2025-07-13
مستخدم تنسيق الوقت المحلي ودليل عرض إزاحة المنطقة الزمنيةعرض التاريخ/الوقت في تنسيق لغة المستخدم مع إزاحة الوقت عند تقديم التواريخ والأوقات إلى المستخدمين النهائيين ، من الأهمية بمكان عرضها في الوقت ...برمجة نشر في 2025-07-13 -
Python قراءة ملف CSV UnicodedEcodeerror الحل النهائيلا يمكن فك تشفير البايت في الموضع 2-3: مقطوع \ uxxxxxxxxx escart string قم بتعبئة المسار إلى ملف CSV مع وضع صغير "r" للدلالة على سل...برمجة نشر في 2025-07-13
-
طريقة قاعدة بيانات MySQL غير مطلوبة لتفريغ نفس المثيلنسخ قاعدة بيانات mysql على نفس الحالة دون التخلص من توفر الطرق التالية بدائل أبسط لعملية التفريغ والاستيراد التقليدية. mysql new_db_name يتضمن ...برمجة نشر في 2025-07-13
-
دليل إنشاء صفحة Fastapi مخصص 404تعتمد الطريقة المناسبة على متطلباتك المحددة. call_next (طلب) إذا كان الاستجابة. status_code == 404: إرجاع RedirectResponse ("https://fasta...برمجة نشر في 2025-07-13
-
طريقة لتحويل أحرف Latin1 بشكل صحيح إلى UTF8 في جدول MySQL UTF8اتصل. لحل هذا ، فأنت تحاول تحويل الصفوف المتأثرة باستخدام "mb_convert_encoding" و "iconv." ومع ذلك ، فإن هذه الأساليب تفشل في...برمجة نشر في 2025-07-13
-
كيفية تبسيط تحليل JSON في PHP للحصول على صفائف متعددة الأبعاد؟تحليل JSON مع PHP يمكن أن يكون تحليل بيانات JSON في PHP ، خاصة عند التعامل مع المصفوفات متعددة الأبعاد. لتبسيط العملية ، يوصى بتحليل JSON كصفيف ...برمجة نشر في 2025-07-13
-
كيفية تحليل الأرقام في تدوين الأسي باستخدام decimal.parse ()؟تحليل رقم من الترميز الأسي عند محاولة تحليل سلسلة معبر عنها في ترميز أسي باستخدام decimal.parse ("1.2345e-02") ، قد تصادف خطأ. وذلك ...برمجة نشر في 2025-07-13
-
كيفية حل خطأ \ "الاستخدام غير صالح لوظيفة المجموعة \" في MySQL عند العثور على عدد أقصى؟كيفية استرداد الحد الأقصى لعد باستخدام mysql حدد ماكس (العد (*)) من مجموعة EMP1 بالاسم ؛ خطأ 1111 (hy000): الاستخدام غير الصحيح لوظيفة المجموعة...برمجة نشر في 2025-07-13
-
كيفية تنفيذ الأحداث المخصصة باستخدام نمط المراقب في Java؟إنشاء أحداث مخصصة في Java لا غنى عن الأحداث المخصصة في العديد من سيناريوهات البرمجة ، مما يتيح مكونات التواصل مع بعضها البعض استنادًا إلى مشغلات...برمجة نشر في 2025-07-13
-
التنفيذ الديناميكي العاكس لواجهة GO لاستكشاف طريقة RPCأحد الأسئلة التي أثيرت هو ما إذا كان من الممكن استخدام الانعكاس لإنشاء وظيفة جديدة تنفذ واجهة محددة. بيان مشكلة على سبيل المثال ، فكر في واجهة...برمجة نشر في 2025-07-13
-
طريقة فعالة Python لإزالة علامات HTML من النصيمكن تحقيق ذلك من خلال تجريد علامات HTML بشكل فعال ، مما يتركك مع النص العادي المطلوب. تحقيق استخراج النص فقط مع MLSTRIPPER PYTHON يأخذ Mlstri...برمجة نشر في 2025-07-13
-
كيف يمكنني تكرار القيم والطباعة بشكل متزامن من صفائف متساوية في الحجم في PHP؟تكرار وطباعة بشكل متزامن من صفيفتين من نفس الحجم المصفوفات: foreach (رموز $ كرمز $ وأسماء $ كاسم $) { ... } هذا النهج غير صالح. بدلاً من ...برمجة نشر في 2025-07-13
-
كيف يمكنني اتحاد جداول قاعدة البيانات مع أرقام مختلفة من الأعمدة؟الجداول مجتمعة مع أعمدة مختلفة ] يمكن أن تواجه تحديات عند محاولة دمج جداول قاعدة البيانات بأعمدة مختلفة. تتمثل الطريقة المباشرة في إلحاق القيم ...برمجة نشر في 2025-07-13
-
كيف يمكنني إنشاء قواميس بكفاءة باستخدام فهم Python؟على الرغم من أنها تشبه إلى حد كبير اختصارات القائمة ، إلا أن هناك بعض الاختلافات الملحوظة. يجب عليك تحديد المفاتيح والقيم بشكل صريح. على سبيل المثا...برمجة نشر في 2025-07-13
-
نصائح لالتقاط الصور العائمة على الجانب الأيمن من القاع واللف حول النصيمكن أن يخلق ذلك تأثيرًا مرئيًا جذابًا مع عرض الصورة بشكل فعال. ضمن هذه الحاوية ، أضف محتوى النص وعنصر IMG للصورة. يمكن أن يبدو رمز HTML مثل هذا: ...برمجة نشر في 2025-07-13















دراسة اللغة الصينية
- 1 كيف تقول "المشي" باللغة الصينية؟ 走路 نطق الصينية، 走路 تعلم اللغة الصينية
- 2 كيف تقول "استقل طائرة" بالصينية؟ 坐飞机 نطق الصينية، 坐飞机 تعلم اللغة الصينية
- 3 كيف تقول "استقل القطار" بالصينية؟ 坐火车 نطق الصينية، 坐火车 تعلم اللغة الصينية
- 4 كيف تقول "استقل الحافلة" باللغة الصينية؟ 坐车 نطق الصينية، 坐车 تعلم اللغة الصينية
- 5 كيف أقول القيادة باللغة الصينية؟ 开车 نطق الصينية، 开车 تعلم اللغة الصينية
- 6 كيف تقول السباحة باللغة الصينية؟ 游泳 نطق الصينية، 游泳 تعلم اللغة الصينية
- 7 كيف يمكنك أن تقول ركوب الدراجة باللغة الصينية؟ 骑自行车 نطق الصينية، 骑自行车 تعلم اللغة الصينية
- 8 كيف تقول مرحبا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 9 كيف تقول شكرا باللغة الصينية؟ # نطق اللغة الصينية، # تعلّم اللغة الصينية
- 10 How to say goodbye in Chinese? 再见Chinese pronunciation, 再见Chinese learning









