”工欲善其事,必先利其器。“—孔子《论语.录灵公》
 浏览:679
来源:https://www.jiqizhixin.com/articles/2024-05-05-4
浏览:679
来源:https://www.jiqizhixin.com/articles/2024-05-05-4
大家好,今天本人给大家带来文章《斯坦福李飞飞首次创业:学术休假两年,瞄准「空间智能」》,文中内容主要涉及到,如果你对科技周边方面的知识点感兴趣,那就请各位朋友继续看下去吧~希望能真正帮到你们,谢谢!
「AI 教母」李飞飞创业了。

 据李飞飞的斯坦福简历显示,她从 2024 年初到 2025 年底处于「Partial Leave」状态。她的研究兴趣涵盖了「认知启发的 AI」、「计算机视觉」和「机器人学习」等领域。
据李飞飞的斯坦福简历显示,她从 2024 年初到 2025 年底处于「Partial Leave」状态。她的研究兴趣涵盖了「认知启发的 AI」、「计算机视觉」和「机器人学习」等领域。


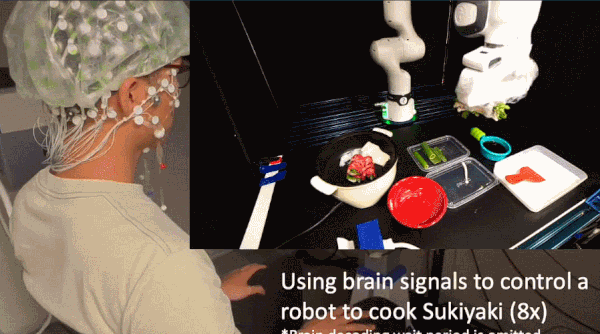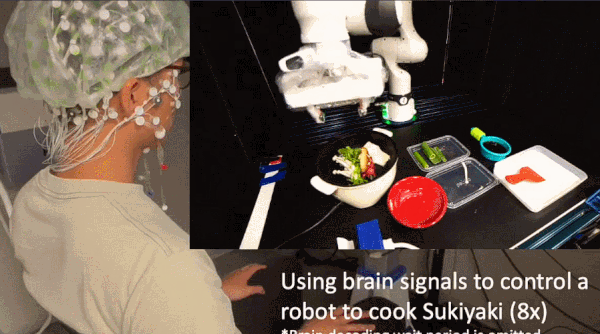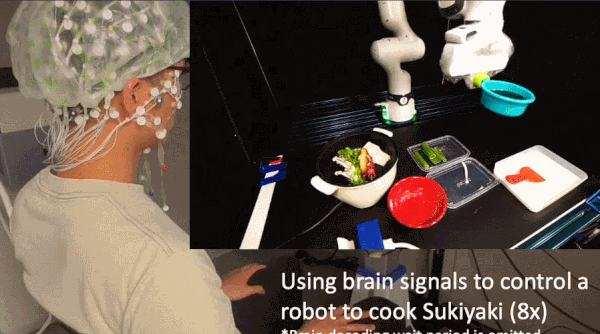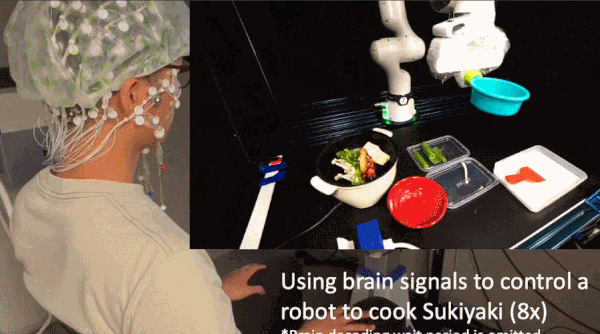
她说:「大自然创造了一个以空间智能为动力的观察和行动的良性循环。」她还补充说,她所在的斯坦福大学实验室正在尝试教计算机「如何在三维世界中行动」,例如,使用大型语言模型让一个机械臂根据口头指令执行开门、做三明治等任务。
这让人联想到2023年李飞飞公布的研究VoxPoser以及VIMA 机器人智能体。
VoxPoser将大模型接入机器人,可在无需额外数据和训练的情况下,将复杂指令转化为具体的行动。
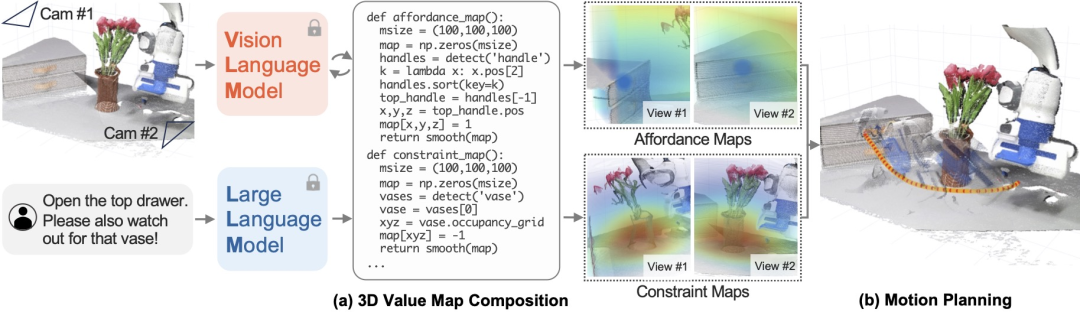
而VIMA 智能体能像 GPT-4 一样接受多模态的(文本、图像、视频或它们的混合 )Prompt 输入,然后输出动作,完成指定任务。
以上就是《斯坦福李飞飞首次创业:学术休假两年,瞄准「空间智能」》的详细内容






免责声明:提供的所有资源部分来自互联网,如果有侵犯您的版权或其他权益,请说明详细缘由并提供版权或权益证明然后发到邮箱:lupingnet@sina.com 我们会在看到邮件的第一时间内为您处理。
Copyright© 2022 湘ICP备2022001581号-3



